数据结构
数据结构碎片
一元多项式
简单数组表示 存储系数和指数,一一对应,运算即分类操作既可
稀疏多项式
记录系数不为零的项 每一项的系数和指数也构成线性表(先系数再指数)
稀疏多项式的运算
新开设新数组C(第三个数组相当于中间存储)
从头开始遍历比较a和b的每一项
指数相同 对应系数相加,和不为0,C中新增加新项;和为0,去掉 即可
指数不相同,将指数较小的项复制到C中
一个多项式已遍历完毕时,将另一个剩余项依次复制到C中即可
顺序存储存在的问题
1.存储空间分配不灵活
2.运算的空间复杂度高
链式存储解决稀疏多项式

线性表中的数据元素的类型可以是简单/复杂类型
线性表的定义类型
基本操作
InitList(&L)
操作结果:构造一个空链表
DestroyList(&L)
初始条件:线性表L已经存在
操作结果:销毁线性表L
ClearList(&L)
初始条件:线性表L已经存在
操作结果:将线性表L重置为空表
ListEmpty(L)
初始条件:线性表已经存在
操作结果:若L为空返回TRUE,否则返回FALSE
ListLength(L)
初始条件:线性表已经存在
操作结果:返回L中数据元素个数
GetElem(L,i,&e)
初始条件:线性表L已经存在,1<=i<=ListLength(L)
操作结果: 用e返回线性表L中第i个数据的值
LocateElem(L,e,compare())
初始条件:线性表L已经存在,compare()是数据元素判定函数
操作结果:返回L中第1个与e满足compare()的数据元素的位序。如不存在这样的数据元素则返回0.
PriorElem(L,cur_e,&pre_e)
初始条件:线性表L已经存在
操作结果:若cur_e是L的数据元素且不是第一个,则用pre_e返回它的前驱否则操作失败,pre_e无意义
NextElem(L,cur_e,&next_e)
初始条件:线性表L已经存在
操作结果:若cur_e是L的数据元素且不是最后一个,则用next_e返回它的前驱否则操作失败,next_e无意义
ListInsert(&L,i,e)
初始条件:L已存在,1<=i<=ListLength(L)+1
操作结果:在L的第i个位置插入新的元素e,L长度+1
ListDelete(&L,i,e)
初始条件:L已经存在,1<=i<=ListLength(L)
操作结果:删除L的第i个数据,并用e返回其值,L长度-1
ListTraverse(&L,visited())
初始条件:L已经存在
操作结果:依次对线性表中每个元素调用visited()
抽象数据类型线性表的定义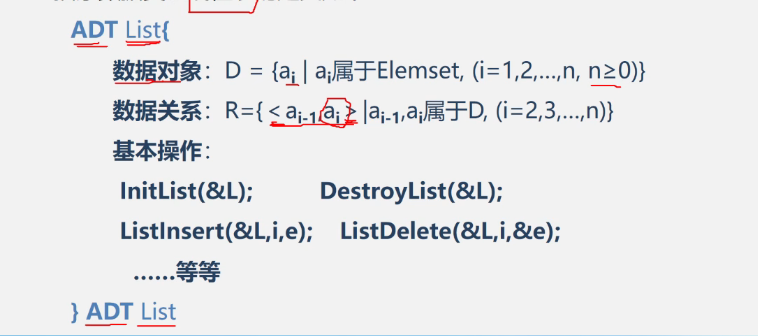
线性表的顺序存储结构
典例:一维数组
定义:把逻辑上相邻的数据元素存储在物理相邻的存储单元中的存储结构。
占用一块连续的存储空间方便计算得出其他元素的存储位置
loc(ai)=loc(a1)+(i-1)×l(存储单元长度)
1 |
|
数组模拟单链表
邻接表(最常用)
存储图和树
空节点下标用-1表示
联邦每个节点存储两个值:内容和指向下一节点指针
顺序表的插入
三步骤:
从后往前赋值
对目标位置进行赋值
列表长度+1
1 | for(int j = L.length;j>=i;j--)//让j=当前列表长度,i后的数据依次后移 |
顺序表的删除
三步骤:
被删除的目标元素赋值给e
把第i个位置的元素前移
列表长度-1
1 | e = L.data[i]; |
单链表的头插法(逆序)和尾插法(正序)


单链表的删除
1.找点要删除单链表的父节点
2.待删除节点的父节点=待删除节点的字节点
3.释放节点
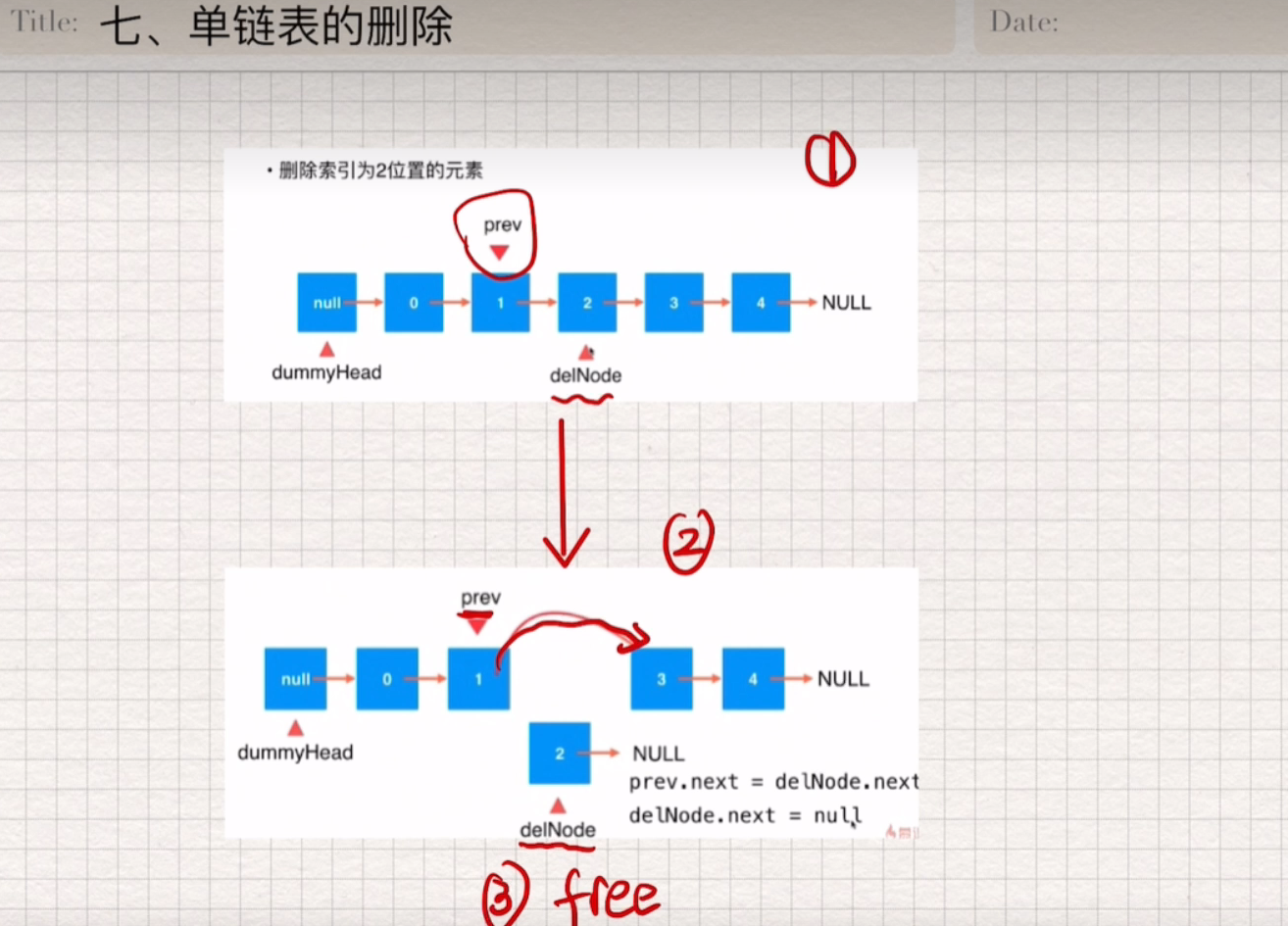
1 | Node prev = dummyHead;//指向头节点 |
双向链表的插入和删除
1.插入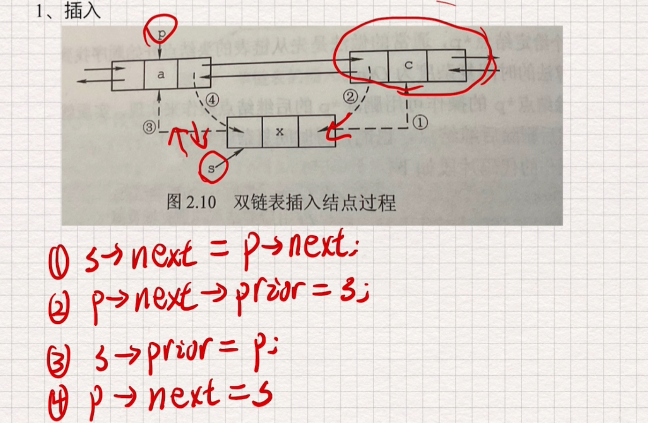
p节点保留相应信息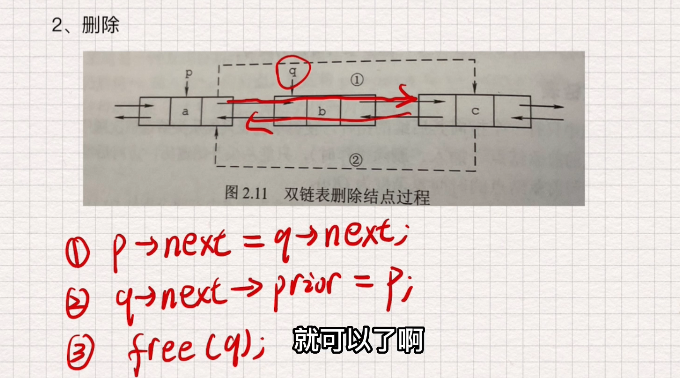
入栈和出栈


队列的入队和出队
队列特点:先进先出

next数组求解
KMP算法
next[i] = 最近匹配字符个数+1
正常第一位数从0开始
nextval数组求解

树节点的计算
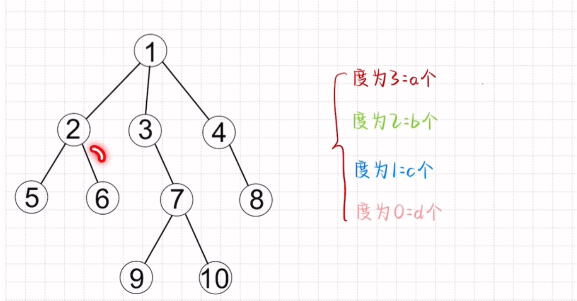
树总结点N = 度数✖对应接节点个数+1(根节点)
上图N = 3a+2b+c+1 = a+b+c+1
满二叉树和完全二叉树
满二叉树
定义
一颗深度为k且有2^k-1个结点的二叉树.
特点
1.每层都是满的
2.只有度为0和2的节点
3.含n个结点的满二叉树高度为log2(n+1)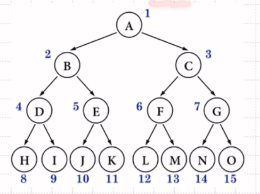
完全二叉树
定义
深度为k具有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树编号为1-n的结点一一对应.
特点
1.叶子结点只可能出现在最下面两层中
2.最下一层叶子结点都依次排列在该层最左边的位置上
3.若有度为1的结点只可能有1个且该结点只有左孩子无右孩子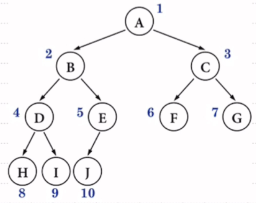
非完全二叉树
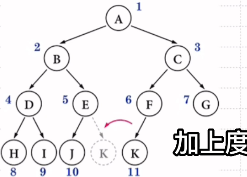
常用公式
$$
叶子结点的数量(n0) = 度为2的结点(n2)+1
$$
$$
n(总节点) = n0(叶子节点)+n1(度为1的节点)+n2(同前) = 2n2+n1+1
n0 = n2+1
$$
二叉树的遍历
先序遍历:根左右
中序遍历:左根右
后序遍历:左右根
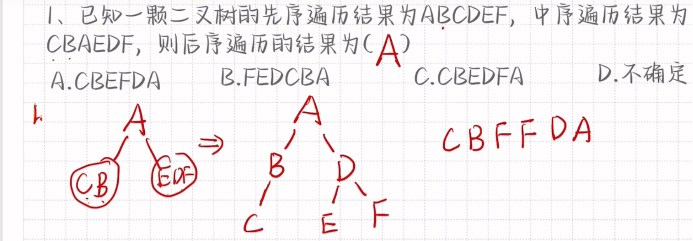
先序遍历第一个为根节点
后序遍历最后一个是根节点
线索二叉树
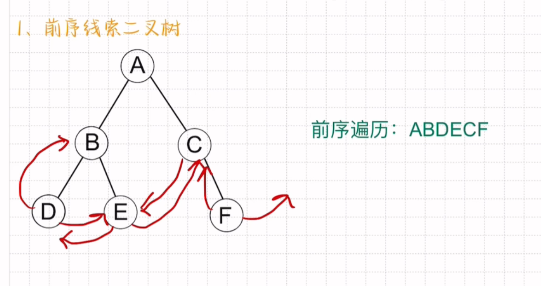
前序线索二叉树
缺少左孩子画出前驱 缺少右孩子画出后继
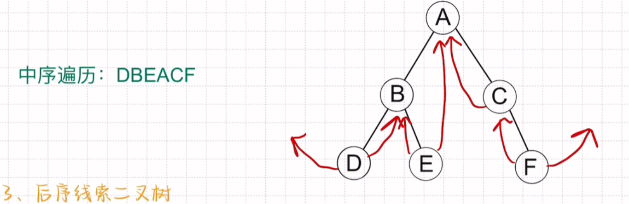
中序线索二叉树
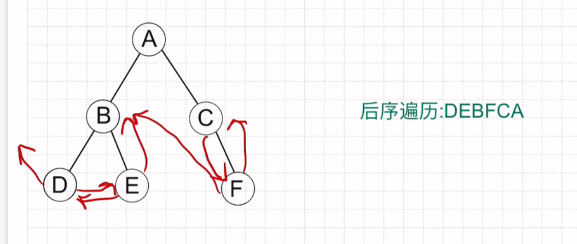
后序线索二叉树
树的存储结构
双亲表示法
根结点无父亲 故为-1
F的父节点是C C的下标是3
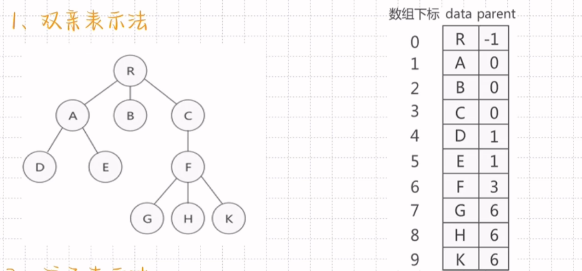
孩子表示法
链式进行存储 查找速度很快
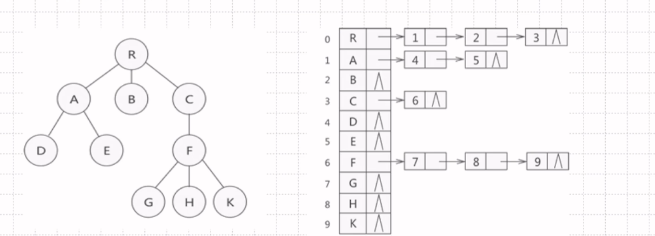
孩子兄弟表示法
兄弟兄弟往下存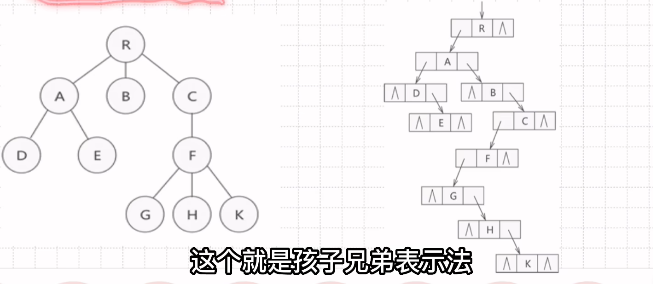
森林、树和二叉树之间的转换
树转换为二叉树
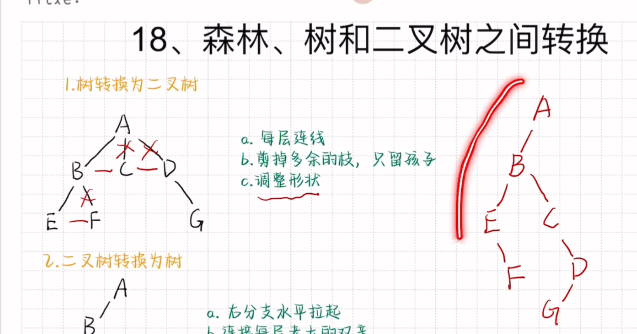
二叉树转换为树
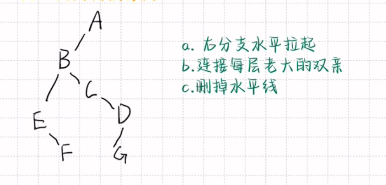
森林转换为二叉树
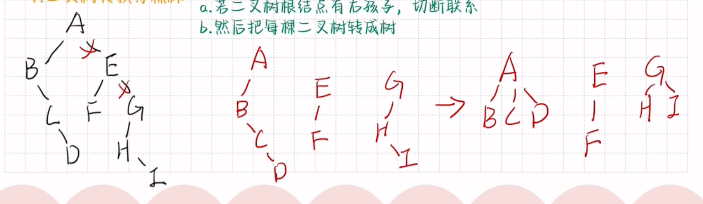
二叉树转换为森林
哈夫曼树的构造
Q:构造19, 21,2,3,6,7, 10,32的哈夫曼树,并计算WPL〔带权路径长度)的值。
Step:
1.选择两个最小结点
2.用计算结点替代原两结点
3.比较运算结果 循环上述步骤
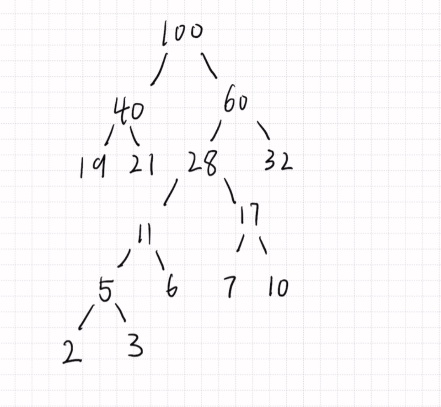
1 | WPL计算:结点值*层数 |
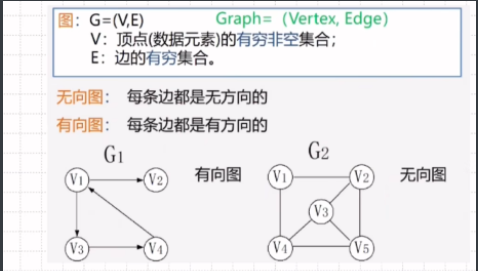
图的定义和术语
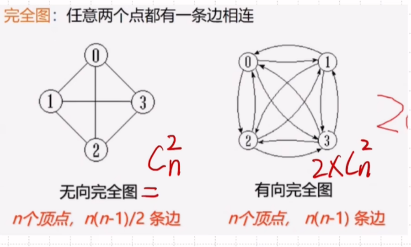
邻接矩阵(图的一种存储结构)
1 | 连通写1 不连通写0 |
无向图的邻接矩阵
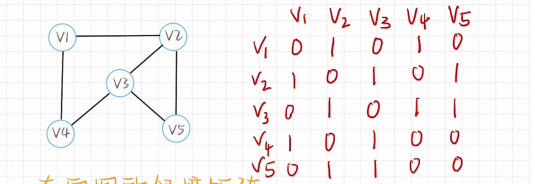 特点:前半部分和后半部分对称
特点:前半部分和后半部分对称
有向图的邻接矩阵

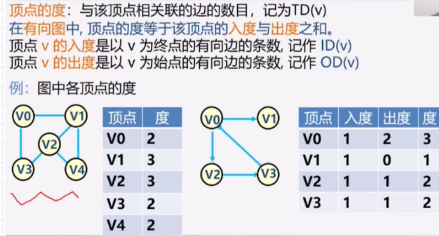
特点:不对称 出度按行求和 入度按列求和
1 | 总度数=出度+入度 |
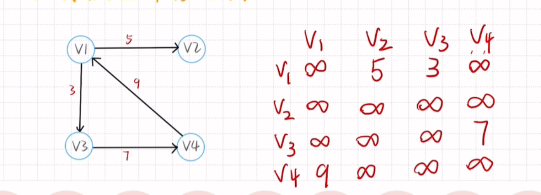
有权图的邻接矩阵
**两个结点无连接填无穷大 **
邻接表法
邻接矩阵存在的缺点:

无向图的邻接表
画出顶点域和边表头指针域
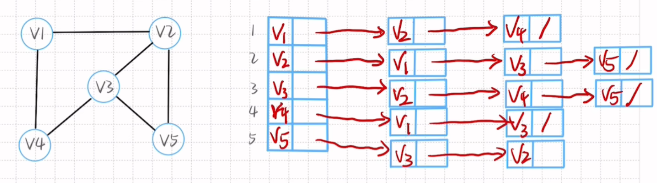 表头指针域无指向的时候用反斜杠
表头指针域无指向的时候用反斜杠
有向图的邻接表
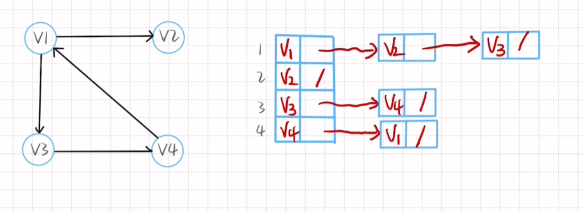
十字链表画法
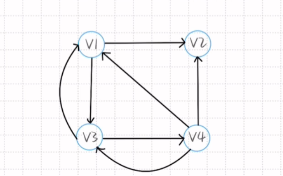
1.写出结点域
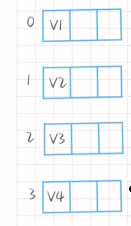
2.开画
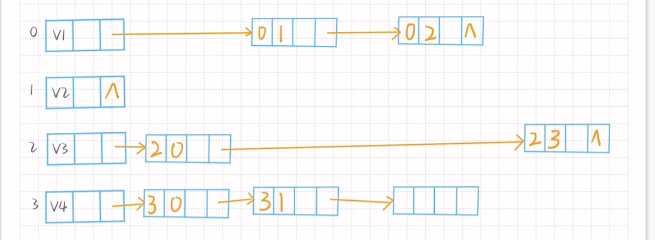
3.找出结点域序号对应的空格进行连接指向+结束符
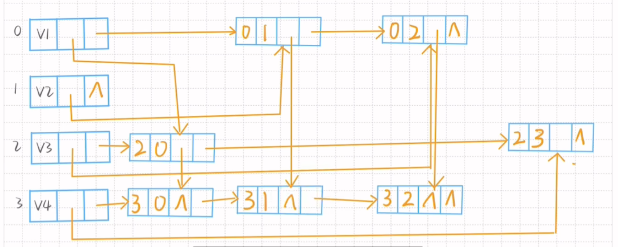
4.按照弧度顺序画图
0,1,2,3
图的广度优先遍历
层层求解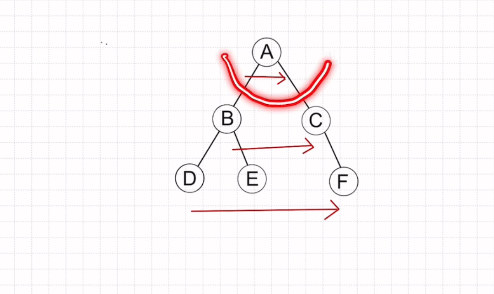
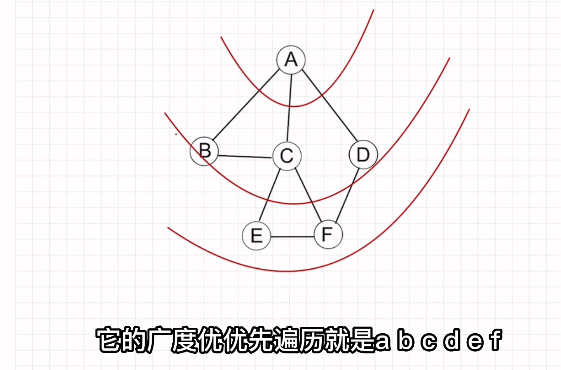
图的深度优先遍历
悬崖勒马
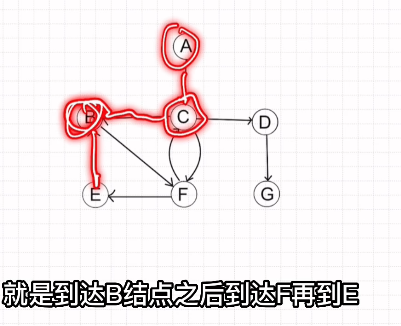
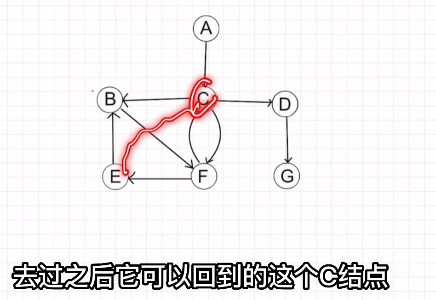
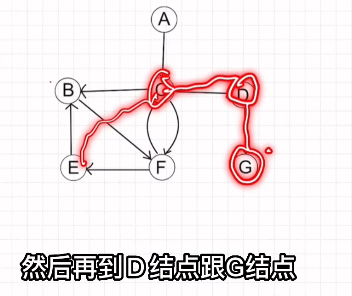
Prim算法(求解最小生成树)
1.从结点出发,优先选择权值较小的边
2.再选择与所选顶点中权值最小的边
3.直到连接所有顶点
注意:连接过程中不能出现环
如图: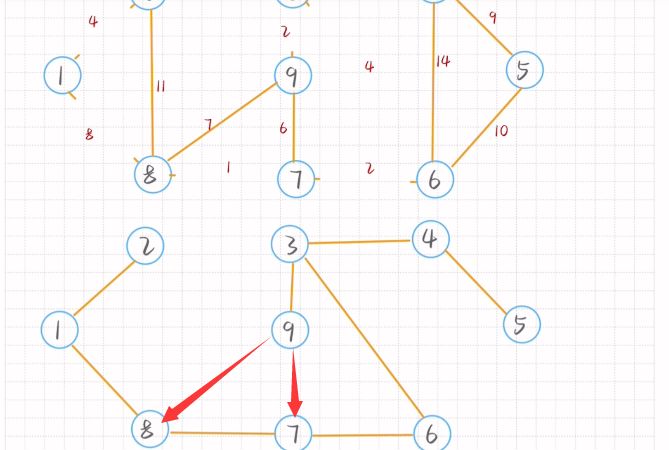
Kruskal算法(最小生成树)
1.找出最小边
2.判断是否有环
3.直到连接所有顶点
最短路径-Dijkstra算法
T:可以确定到达
F:无法确定到达
dis:距离
无法直接到达填无穷大
换点求值的dis若小于原dis需更新将其更新为dis
从1点出发到达每个结点的最短路径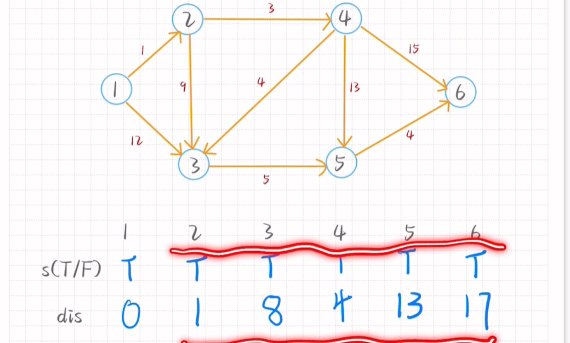
最短路径-Floyd算法
行:起始点
列
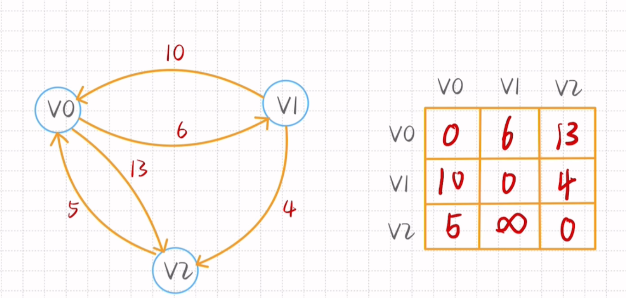
去掉出发点结束点以及斜对角(即所求点所在的行和列行列)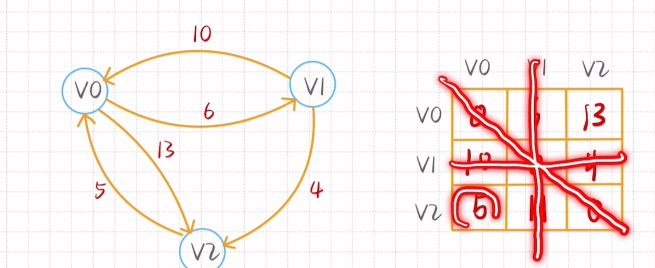
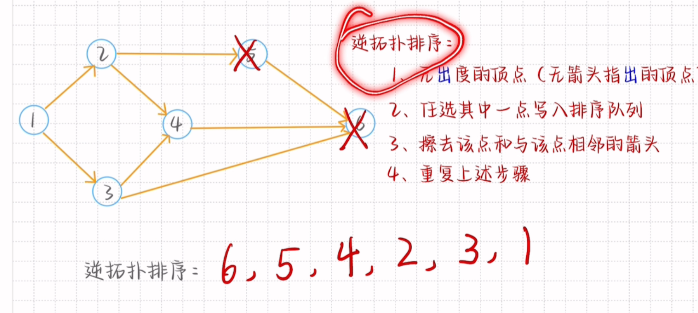
拓扑排序和逆拓扑排序
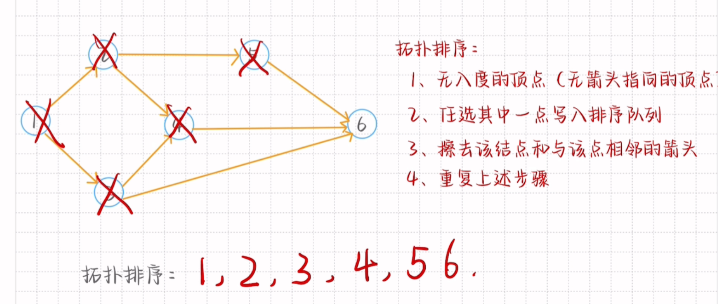
AOE网中的关键路径
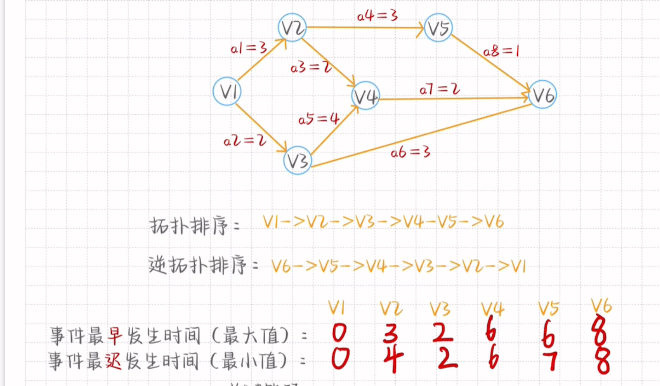
最迟发生时间从v6开始计算 事件发生的最早时间-对应权值
关键路径:最早时间和最迟时间相等的点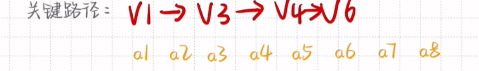

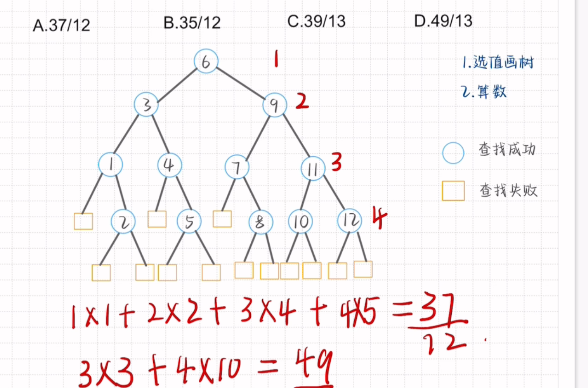
平均查找长度-折半查找
Step:1.选值画树
2.算数
先找根节点(向下取整) 再依次找出左右孩子(均值且向下取整)
查找成功的补上所缺的孩子 叶子节点补上左右孩子
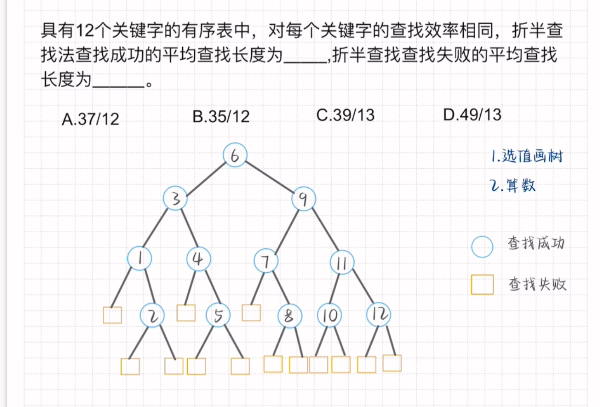
1 | 每一层的层数*对应节点数 |
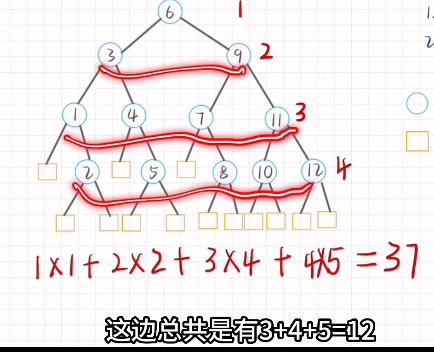
注意:查找失败的叶子节点计算层数往上抬一层(即减少一层)
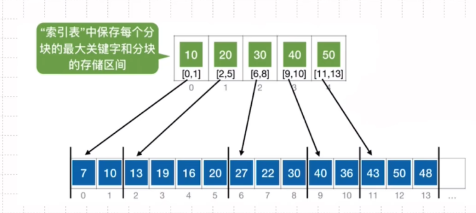
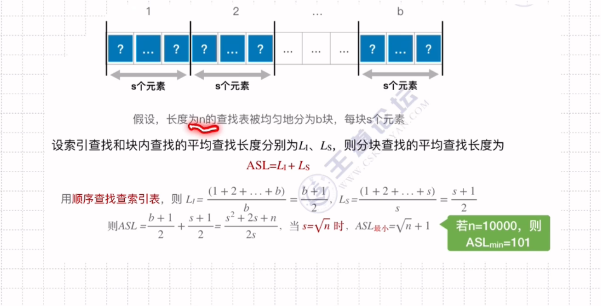
平均查找长度-分块查找
分块:块内无序,块间有序

平衡二叉树
1.平衡二叉树左子树和右子树高度之差不超过1
2.以不平衡二叉树的根节点开始,沿着加入的结点方向与之相邻的三个结点进行调整
大于->右孩子 小于->左孩子
48为根节点 左孩子的度数为0 右孩子的度数为2 需调整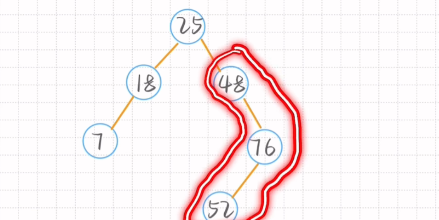
找到与根节点(包含根节点)相邻的三个结点找到中间值 进行左右孩子调整后移到原来位置【特别注意单长分支】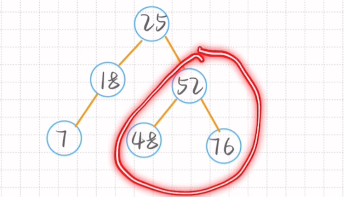
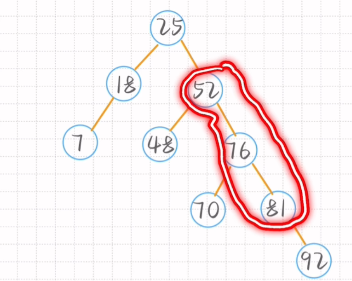
记得左边孩子也要调整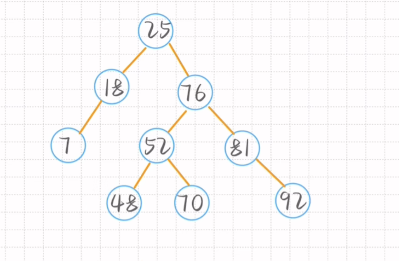
红黑树
定义
特殊的二叉排序树,主要用它存储有序的结构,查找操作时间复杂度O(log2n)
特性
1.每个结点红色/黑色
2.根节点是黑色的
3.叶节点(外部结点、NULL结点、失败结点)均是黑色的
4.不存在两个相邻的红结点(即红结点的父节点和孩子都是黑色的)每两个红色结点之间必有一个黑色结点进行间隔
5.对于每个结点,从该节点到任一叶结点的简单路径上,所含黑结点的数目相同
1 | 左根右(左孩子小于右孩子) |
B数
定义
多路平衡查找树
B树的阶:B树中所有结点的孩子个数的最大值(m)
空树:m阶B树
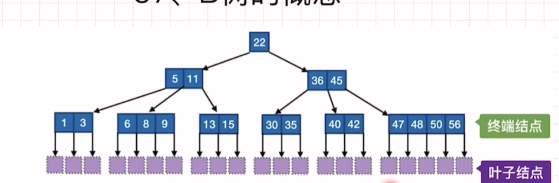
叶子结点实际是空指针(指向NULL)查找失败之后指向空值
终端结点指向实际值
特性
1.树的根结点至多有m颗子树,即至多含有m-1个关键字
2.若根节点不是终端节点,则至少有两颗子树
3.除根节点外的所有非叶节点

从左到右以此增大
散列表处理冲突的方法
线性探测法
用散列函数进行求解 有冲突往下求解

平方探测法
首先用散列函数进行查找 有冲突用di从0的平方开始
顺延可以往前也可以往后
双散列法
有冲突对两个散列表长度进行相加求解取mod

i = 冲突的次数(递增)

4的位置已被占 此时用Hi公式 0+1*4 = 4又回到4的位置被占用 递增i
i = 2 Hi = 0 + 4 * 2 = 8
直接插入排序算法
Step
1.选取一个数并将其作为有序序列
2.每一轮排序将后面的一个数加入改序列
3.直到最后一个数
折半插入排序
Step
1.选取一个数并将其作为有序序列
2.每一轮用折半查找法将后面的一个数加入到该序列
3.直到最后一个数

初始位空余用来排序 默认第一位是有序序列 从第二位开始 将第二位移到0位

选取数小于mid high指针前移(mid向上取整)
选取数大于mid low指针后移
low ==high 时结束排序
希尔排序
1.间隔分组(通常为总长度的一半)
2.组内排序
3.重新设置间隔分组(为前一次分组的一半)
4.重新插入排序

组内排序

同样组内排序直至分为一组
冒泡排序
step
1.依次比较两个相邻元素
2.若无序就交换位置,将较大值放在后面
快速排序
Step
1.选定一个数为中心轴(通常为首位)
2.将小于该数字的元素放在左边
3.将大于该数字的元素放在右边
4分别为左右子序列重复前三步操作

选中轴移到最开始位置(0)
从右边开始排序(high)找到比中心轴的值小开始从左比较
low和high重合排序结束
简单选择排序
Step
1.从头到尾扫描序列,找到最小元素与第一位进行交换
2.从剩下的无序队列中选出最小元素与第一位进行交换,以此类推
整个数组有8位经过8次交换

堆排序(选择排序)
Step
1.生成完全二叉树
2.从第一个非叶子结点:n/2-1 开始调整(n:序列长度 )
一共4层长度为8 8/2-1 = 3 97开始

大根堆:父节点大于子结点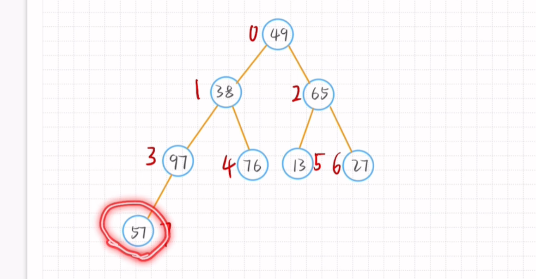
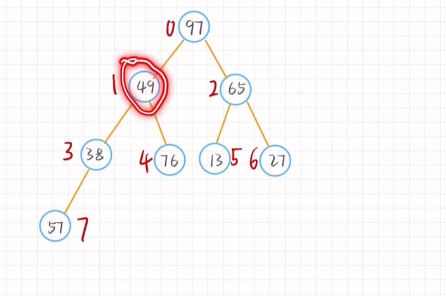
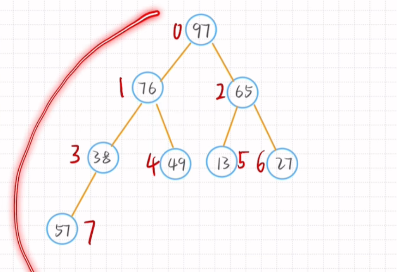
插入元素后进行调整只需对根节点到新增节点进行调整
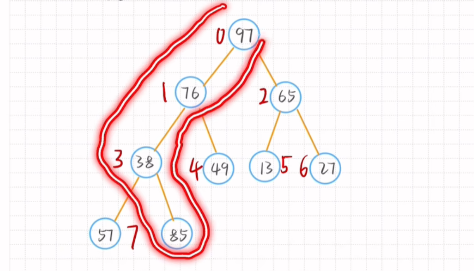
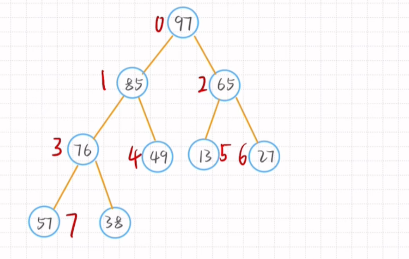 删除元素后只需将尾节点移动到首节结点的位置
删除元素后只需将尾节点移动到首节结点的位置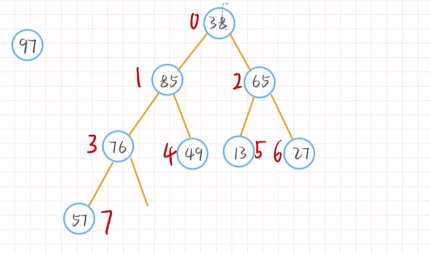
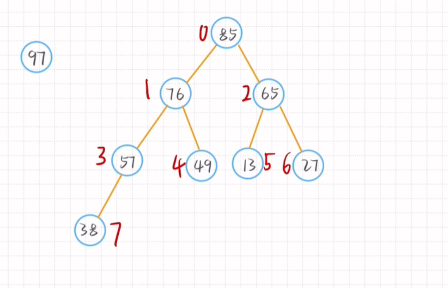
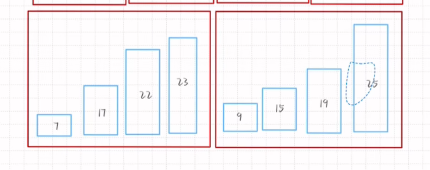
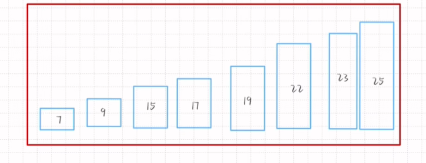
归并排序
Step
1.开始每个数字作为一组
2.每次进行前后两个数的两两比较 直到最后一组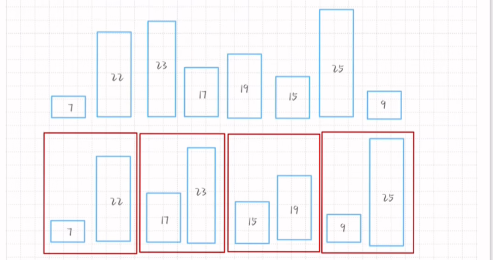
基数排序
step
1.将数字按位分割成多个部分
2.根据每个部分信息将数字进行分配
3.将数字依次收集 组成新的排序结果
个位
十位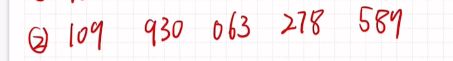
百位
排序算法总结
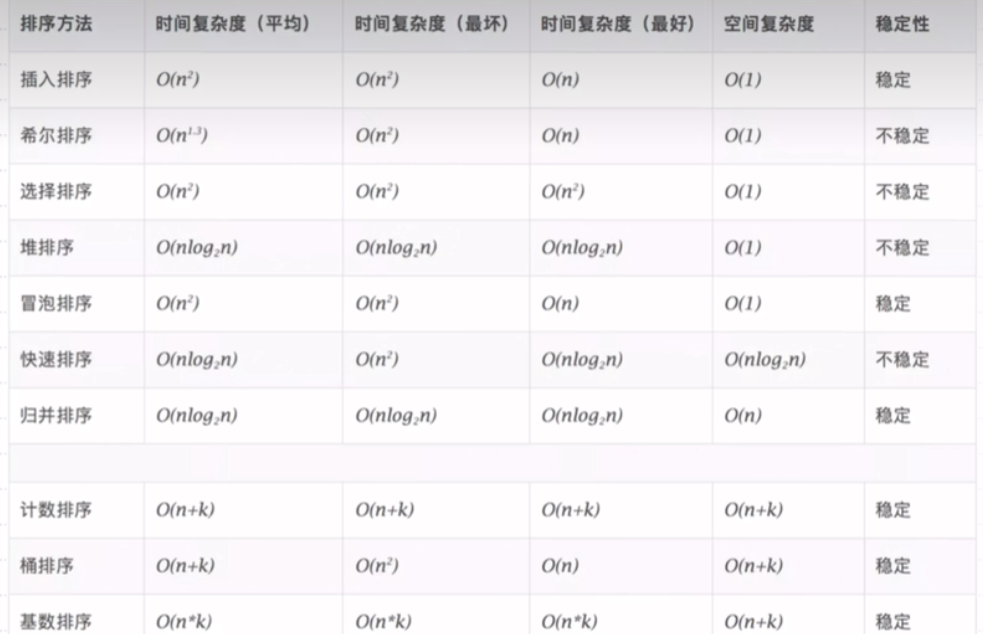
有两只动物,一只叫插帽龟,另一只叫统计鸡,它两做事情都很稳,其中插帽龟喜欢插帽子,统计鸡喜欢做统计(加减乘除)。
但有一天,插帽龟在选择帽子时候,掉了帽子就慌(方 n^2)了,还好被恩人(nlog)捡到快速归还给对方(堆).
